

Vaste sujet deep dive de nombreux passionnés VMware qu’est le vNUMA. Il a longtemps été un sujet complexe pour de nombreux architectes VMware mais aujourd’hui avec les optimisations effectuées par la R&D VMware il est plus simple et moins contraignant de gérer le vNUMA, et ce depuis la version vSphere 6.7 (sans compter vSphere 8 qui a totalement aboli le fameux « Cores per socket » et qui l’a remplacé par « assigned at power on ».)
Dans le billet d’aujourd’hui nous allons donc démontrer ces optimisations sur la version vSphere 7.0 U3 à travers vCloud Director qui, d’ailleurs lui aussi apporte son lot d’optimisations vCPU pour gérer au mieux son capacity planning avec la notion de « vCPU Speed. »
Ce billet sera décomposé en deux parties.
La première partie sera consacrée à vNUMA et sa topologie au sein des VMs, et la seconde partie sera quant à elle consacrée à vCloud Director et ses optimisations/spécificités.
Qu’est-ce que le vNUMA, et comment une VM se comporte face à cette topologie ?
Le vNuma est une topologie qui est connue depuis un bon nombre d’année, et c’est d’ailleurs parce que ça été un « casse-tête » pour les architectes VMware qui devait optimiser au mieux leurs workloads que cette topologie est connue.
Rentrons maintenant dans le vif du sujet, un « Numa Node » est l’association d’un processeur physique et de ses slots mémoire au sein d’une carte-mère.
Un exemple concret d’un nœud VxRail V670F :
– Intel(R) Xeon(R) Gold 6354 CPU @ 3.00GHz (2x CPU physique)
– Cores per socket : 18
– Logical Processors: 72
– Hyperthreading enabled
– RAM: 1024Go (à diviser par deux, 512Go par socket)
Il faut comprendre que chaque « Numa Node » est en réalité composé d’un CPU physique Intel Gold 6354 de 18 « Cores per socket » et de 512Go pour un total de « 2 Numa Node » sur la carte-mère. Nous avons donc 36 Cores per socket et 1024Go RAM.
((18 Cores per socket * 2 CPU physiques) + (512Go RAM * 2)).

Avec cet exemple nous pouvons d’ores et déjà déterminer plusieurs limitations, et ce sans même rentrer dans les détails si une VM venaient à avoir 32 vCPU et 768Go de RAM (elle serait répartie physiquement sur les 2 sockets pour la partie CPU et RAM).
Parmi les limitations nous pouvons citer le QuickPath Interconnect qui est devenu le Ultra Path Interconnect avec la génération Skylake (passage à 10.4 GT/s sur les liaisons point-à-point entre les 2 processeurs), la latence mémoire entre les 2 processeurs, et le mauvais mappage des Numa Node qui est propre au monde de la virtualisation.
Petite aparté pour les expert VMware :
Nous sommes totalement d’accord pour dire que dans ce cas-là il n’y a presque aucun intérêt, mais attention je dis bien « presque » parce qu’il y aura toujours des avantages à faire de la virtualisation avec des workloads qui pourraient prendre 80% de RAM et qui pourraient prendre toute la charge CPU plutôt que du baremetal, ne serait-ce que pour la partie « reserved CPU/Memory » pour le HA.
Alors oui les chiffres sont démesurés mais c’est pour l’exemple afin d’apercevoir les limitations côté ESXi (limitation, qui je le rappelle ont été grandement optimisée aujourd’hui).
Comportement des OS face à vNUMA
Tout d’abord notons une chose assez importante qui va vous être utile pour comprendre la suite de ce chapitre.
Par défaut la topologie vNUMA est présentée à l’OS à partir de 8 vCPU seulement
Les commandes de bases permettant de vérifier la topologie vNUMA sont :
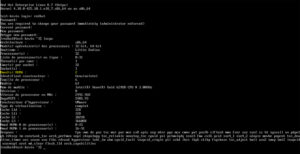
- Linux : « lscpu » pour Linux
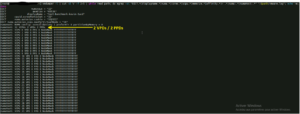
- ESXi : « sched-stats -t numa-clients » et « vmdumper » pour l’ESXi
- Voire « esxtop » en mode « m » + les paramètres vNUMA
- Windows à plusieurs choix possibles.
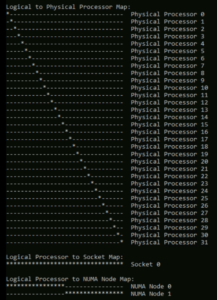
- Soit utiliser des outils tiers tel que coreinfo, CPU-Z,..
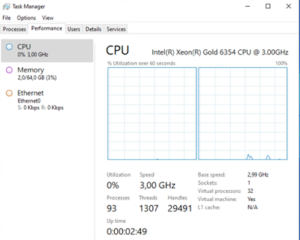
- Soit utiliser la partie « Task Manager » intégré à Windows via « taskmgr » puis « performance »
Linux :
ESXi :

Windows :
Ici nous pouvons voir qu’une VM sous Windows affiche bien 1 socket avec 32 vCPU.
Coreinfo:
Représentation logique des cœurs sous « Coreinfo »
Pour rappel depuis la version vSphere 6.7 le comportement des VMs face à la topologie vNUMA a totalement été améliorée, et aujourd’hui le paramètre « Cores per Socket » n’a plus aucune influence sur la présentation de Numa sur la VM. C’est d’ailleurs ce que nous allons démontrer ci-dessous et sur le prochain chapitre consacré aux perfs VMs.
VM ayant une configuration de « 16 vCPU » / « 2 Cores per Socket » et « 128Go RAM » aura sa représentation vNuma telle que présentée :
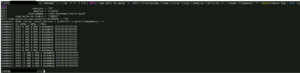

Les informations importantes la commande « sched-stats -t numa-clients » sont :
- groupName
- homeNode
- nWorlds
- vmWorlds
- localMem
Nous avons donc une VM qui tourne sur le « Numa Node 1 » avec 16 vCPU, si le vCPU ou la RAM dépasserait la valeur physique de l’ESXi il y aurait une seconde ligne avec le même groupName mais voyons cela de plus près avec, cette fois-ci, une VM qui dépasse très largement le sizing CPU & RAM que peut gérer un processeur physique.
Une VM ayant une configuration de « 32 vCPU » / « 32 Cores per Socket » et « 768Go RAM » aura sa représentation vNuma telle que présentée :
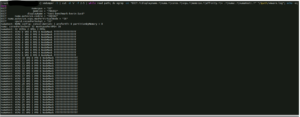
Ici nous voyons bien les deux groupName identiques ce qui veut dire que la VM est distribuée sur les 2 Numa Node de la carte-mère. C’est ce qu’on appelle une « Wide VM » dans une topologie vNUMA.
Une VM peut être « Wide» pour principalement 2 raisons, c’est soit parce qu’elle dépasse la configuration physique CPU soit parce qu’elle dépasse la configuration physique de la RAM.
Pour rappel notre infrastructure de test est composée de deux socket de 18 CPU et 512Go de RAM chacune. En chiffre, une VM peut donc être configurée avec maximum 18 vCPU et 512Go, dans le cas contraire elle sera forcément considérée comme « Wide VM ».
Mais est-ce qu’une Wide VM est moins performante qu’une VM « non Wide » ? Il est temps de passer au chapitre suivant pour le savoir.
Benchmark des VMs avec modification du vCPU et de la valeur Core per Socket (CPS).
Au chapitre précédent nous avons vu comment vérifier la topologie sur les clients, nous pouvons donc passer aux tests :
les modifications vCPU et les benchmarks.
Les bases de ce chapitre :
- L’ensemble de ces tests ont été effectués sur un ESXi dédié d’un cluster de 3 nœuds VxRail en version 7.0.400
- Aucune autre VM mis à part le vCLS ne tournait
- L’hyperthreading a été activé
- Nous ne sommes pas dans une configuration SCAv1 ni SCAv2
- Boot.hyperthreadingMitigation => false
- Boot.hyperthreadingMitigationIntraVM => true
- L’EVC désactivé
- Le « Performance Mode » de l’ESXi est en High Performance
- Le « CPU Hot Add » et le « Memory Hot Add » ont bien été désactivés
- La VM était une Windows 21H2 (OS Build 20348.707)
- AIDA 64 Extreme v6.85.6300
- Passmark PerformanceTest 10.2
- Nous ne sommes pas dans une configuration SCAv1 ni SCAv2
Nous pouvons donc nous apercevoir que globalement les scores sont plus ou moins identiques, en tout cas il n’y a pas d’écart considérable entre les 3 configurations, mais il est à noter tout de même que le « CPU Scheduler » gère mieux la majorité des uses case lorsque la VM est alignée sur la configuration physique (16 vCPU / 1 CPS)
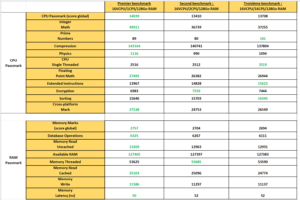
Comparaison d’une VM 16 vCPU / 128Go RAM.
Les benchmarks précédents représentent des VMs « non Wide » qui tourne sur le « Numa Node 0 » car elle a 16 vCPU contre 18 CPU physique et 128Go de RAM alors que le Numa Node 0 en compte 512.
Sur les premiers chiffres qui sortent on peut voir que les scores global CPU de Passmark sont plus ou moins identiques (les variations sont très certainement dues aux charges au sein de l’ESXi à l’instant t :
- 14039 pour la 16 vCPU / 1 CPS
- 13410 pour la 16 vCPU / 2 CPS
- 13708 pour la 16 vCPU / 16 CPS
Et concernant le score global RAM nous somme sur du :
- 2757 pour la 16 vCPU / 1 CPS
- 2704 pour la 16 vCPU / 2 CPS
- 2694 pour la 16 vCPU / 16 CPS
Nous pouvons donc en conclure que la topologie vNUMA n’a vraiment plus aucun impact à l’heure où nous utilisons majoritairement du vSphere 7.0 à minima (oui oui j’espère que c’est bien le cas 😊et surtout parce que le EoGS de vSphere 6.7 était au 15 octobre 2022). Le vNUMA n’est donc aujourd’hui qu’une question de licence par socket au sein des VMs et non de performance pure, il y a d’ailleurs beaucoup de clients qui consomme des services au sein de cloud provider (ou On-Premises) qui peuvent faire des économies de licences en jouant encore sur ce paramètre.
A ce sujet, il y aura un autre article dédié à l’optimisation d’une infrastructure full stack VMware (VCF, vSAN,NSX-T,…) au sein d’un Cloud Provider qui utilise vCloud Director.
Bonus : Qu’est-ce que le paramètre « PreferHT » et comment interfère-t-il sur les performances ?
En rédigeant ce billet je suis tombé sur un « Advanced parameter côté VM qui date de plusieurs années mais qui est encore d’actualité : le « PreferHT ».
J’ai donc décidé de vérifier son impact sur les workloads de différentes façons :
- Ceux qui sont considéré « Non Wide »
- Ceux qui sont considéré « Wide VM »
- Dépassement par le vCPU
- Dépassement par la RAM
Qu’est-ce que le PreferHT ? D’après VMware sur un blog de 2014 il ne s’agit pas d’exposer les cœurs logiques aux VMs comme l’on pourrait le penser mais plutôt de profiter du cache L3 du processeur tout en étant sur un même Numa Node. Techniquement ce paramètre va prendre le dessus sur l’automatisation du Scheduler vNUMA en bypassant la répartition sur les Numa Node.
En soit il n’y a pas vraiment de documentation officielle sur le sujet, mais les cas d’usages associés à ce type de configuration serait liée aux VMs ayant plus de RAM configurée que de vCPU, ce qui forcera le Scheduler à prendre un maximum de RAM au sein d’un seul nœud NUMA, et ainsi éviter l’inter-link entre les deux sockets (QPI / UPI) qui pourrait engendrer de la latence par exemple.
Exemple concret, si une VM à 768Go de RAM sur notre infrastructure d’exemple elle sera répartie équitablement de 384Go sur le Numa Node 0 et 384Go sur le Numa Node 1, seulement si elle n’a pas de « PreferHT » dans ses Advanced Parameters.

NHN : 0/1 (HomeNuma 0 & HomeNuma 1)
GST_ND0 : 394192 Mo
GST_ND1: 392192 Mo
Le Scheduler a donc bien fait le travail en divisant équitablement la RAM en 2 (384Go par Numa Node).
Si nous prenons une VM qui cette fois-ci est configurée avec le paramètre PreferHT elle ne sera plus répartie équitablement mais elle sera placée de manière à prendre le maximum de ressource sur le NumaNode 0 tel que :
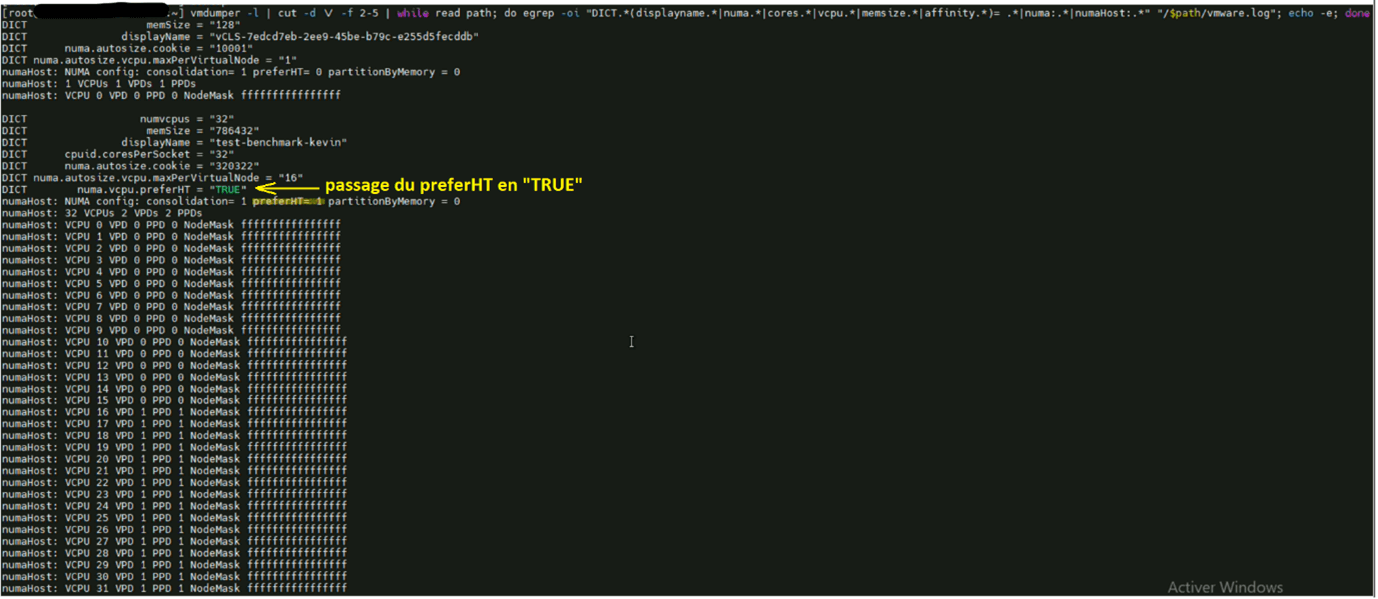

Nous avons donc NHN 1 avec ~260Go et 0Go sur le NHN 0 mais il y a un point intéressant sur cette répartition NHN.
Tant qu’un processus RAM ne va pas consommer au-delà du NumaNode 0 la VM restera sur ce NumaNode, mais dès qu’un processus dépasse le seuil de ~260Go (exemple un test OCCT) elle basculera en NHN 0/1 mais toujours en privilégiant le maximum de RAM sur le NHN 1. Autre fait intéressant c’est que la VM sera toujours indiquée en NHN 0/1 même après l’arrêt du processus et que la seule action qui la refait basculer sur le NHN 1 est un « PowerOff » (un reboot n’a aucun effet sur le Numa dans ce contexte).
Threads côté Windows :

Après charge OCCT :

Nous voyons ici qu’après la charge OCCT la VM bascule bien en NHN 0/1 avec 468Go sur le NHN1 qui est son NumaNode préféré et 263Go sur NHN 0, passons maintenant aux performances.
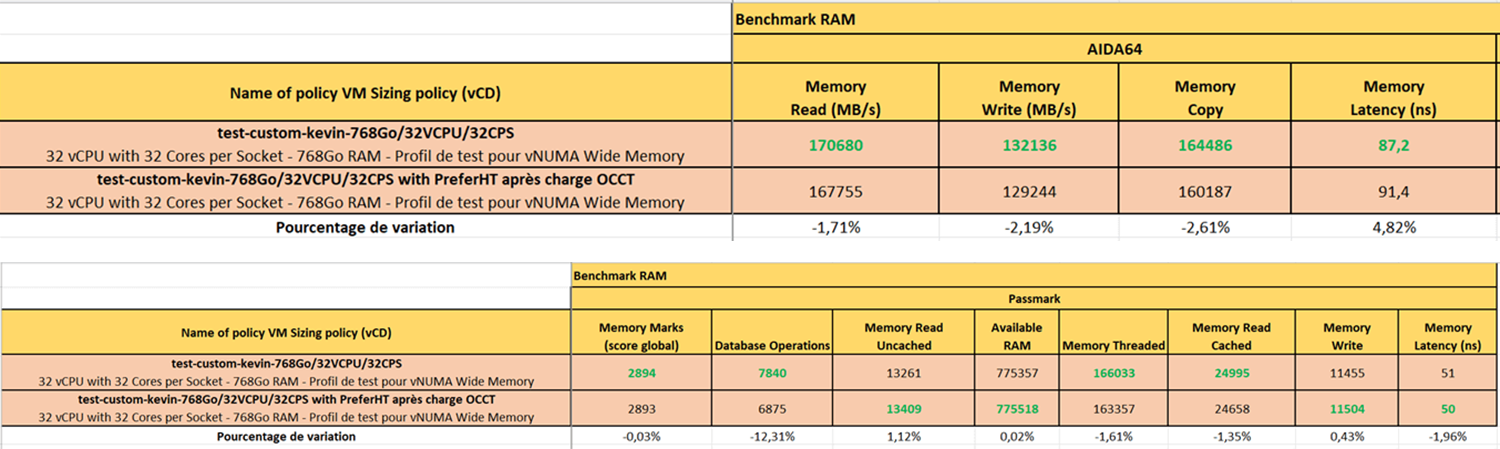
Sans surprise le paramètre PreferHT n’est pas du tout avantageux pour les workload côté RAM parce que nous avons jusqu’à 12,31% de perte sur les Database Operations,


Côté CPU, c’est une toute autre histoire et nous voyons très clairement l’avantage du PreferHT avec jusqu’à 99,67% de gain !
Conclusion
L’ensemble de mes tests se sont tous déroulés sur un ESXi d’un cluster de 3 nœuds qui ne contiennent aucun workload autre que qu’une seule VM de test. Il y a un gain de performance non négligeable en activant ce paramètre, mais sur un cluster constitué de heavy et light workload les gains devraient être d’approximativement ~20% en moyenne et non 40,69% comme ci-dessus.
En résumé le conseil que j’ai à vous donner : testez avant d’activer.
Maintenant que l’ensemble des bases vNUMA ont été décrite dans cet article nous pouvons passer au suivant:
Comment un cloud provider optimise les workloads de ses clients ?
En avance de phase, je vous donne une petite idée sur ces technos que vous connaissez (déjà peut être bien) DRS, HA, vSAN Stretched Cluster, iOPS, vCPU Speed, et j’en passe.
Kévin DOS SANTOS, Consultant VMware Cloud




