

Ce n’est pas nouveau, les Datacenters sont les salles serveurs qui hébergent l’ensemble des équipements informatiques d’une entreprise. Je sais jusqu’à là je ne vous apprends rien.
Mais que se passe-t-il si mon système d’information (SI) n’est plus disponible ? Quelles en sont les conséquences, causes et surtout comment s’en prémunir. Est-ce que je dispose de l’ensemble des procédures et outils pour me protéger d’un incident critique ? C’est clairement un sujet complexe et plusieurs solutions techniques permettent d’y répondre. L’une des réponses est la mise en place d’un PRA (Plan de Reprise d’Activité). Je sais, le sujet du PRA est relativement vaste et complexe voire impossible de traiter dans son intégralité, il faudrait idéalement un site dédié à cela ! Je vous recommande notre livre blanc disponible ici qui liste les bonnes pratiques autour du PRA ainsi que la stratégie de reprise à mettre en place, en utilisant la solution VMware Cloud Disaster Recovery (VCDR).
Dans cette série de 3 articles, nous voulons nous concentrer sur l’utilisation de VCDR dans un contexte de Ransomware (sans rentrer dans les détails du process organisationnel du PRA en lui-même), en passant par la mise en place de la solution jusqu’au déroulement d’un Plan de test de reprise d’activité. Quel programme !
Vous êtes confortablement installé avec votre tasse de café ? Nous oui. Alors allons-y et bonne lecture !!! 😊
Parlons du contexte actuel du SI
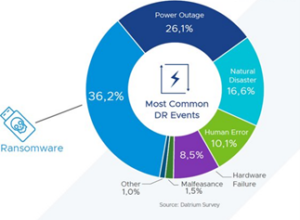
Aujourd’hui, le Système d’Information doit être opérationnel en tout temps et son indisponibilité est chaque jour plus critique et coûteuse pour les entreprises. La disponibilité est conditionnée par de nombreux facteurs tels qu’une coupure électrique, un désastre naturel (inondation, incendie), une erreur humaine, une défaillance matérielle, un arrêt de la climatisation, …
D’après une étude réalisée par Datrium, on constate que la 1ère cause de panne aujourd’hui est liée à des actes de cyber malveillance comme les Ransomwares.
En réponse, les entreprises doivent disposer d’un Plan de Reprise d’Activité pour faire face à cette menace mais ce n’est pas suffisant. La conservation inaltérable des données et la capacité à redémarrer sur une infrastructure performante et disponible est essentielle. Le choix de la technologie qui permet la reprise d’activité est conditionné par 2 critères essentiels.
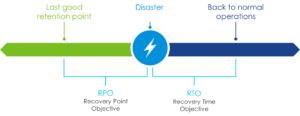
- Le Recovery Point Objective: Il s’agit de la perte de données acceptable pour l’entreprise. Le RPO va dépendre du temps nécessaire entre 2 externalisations de données.
- Le Recovery Time Objective: Il s’agit de la coupure de service acceptable entre le sinistre ou l’arrêt de production et le retour en fonctionnement nominal. Ce temps inclut le délai nécessaire aux équipes pour diagnostiquer l’incident et décider de lancer la reprise d’activité. Dans le cas d’un incident cyber, il faut aussi ajouter le délai nécessaire à l’identification d’un point de rétention fiable pour redémarrer.
La sécurisation du Système d’Information se concentre sur 2 piliers essentiels :
- Préventif : Eviter la compromission du système d’information grâce à des outils de sécurité efficaces, la sensibilisation des utilisateurs, la revue des processus d’exploitation du SI et l’analyse des événements de sécurité. L’objectif est de tout prévoir pour réduire au maximum le risque d’attaque.
- Curatif: Permettre le redémarrage en cas d’attaque en se basant sur des points de rétentions inaltérables et fiables. L’objectif est de prévenir l’imprévisible en permettant de redémarrer l’activité dans une bulle étanche et fiable en cas d’attaque au travers d’un plan de reprise d’activité.
Nombreuses entreprises possèdent déjà une infrastructure de reprise d’activité. Elle est souvent l’ancienne plateforme de production. Il est donc complexe de la maintenir, d’en assurer la disponibilité, l’évolutivité et la performance. De plus, ces environnements ont un impact important en termes de consommation de place dans les racks mais aussi électrique. S’appuyer sur une offre d’Infrastructure as a Service permet de s’affranchir de ces problèmes, d’assurer la reprise d’activité en toute sécurité et performance tout en répondant aux enjeux de Green IT.
VMware propose de répondre à ces enjeux via l’utilisation d’une solution de Disaster Recovery as a Service(DRaaS) VMware Cloud Disaster Recovery.
VMware Cloud Disaster Recovery (VCDR), c’est quoi ?
VMware Cloud Disaster Recovery est le service de reprise en cas de sinistre de VMware distribué sous la forme de solution SaaS. Il protège les machines virtuelles vSphere du client via une réplication dans le cloud.
VCDR permet entre autres de :
- Conserver de nombreux points de rétentions dans un cloud sécurisé et isolé des environnements du client,
- Redémarrer rapidement l’activité dans une architecture VMware Cloud on AWS en démarrant les machines directement depuis les points de rétentions jugés fiables,
- Naviguer dans points de rétentions sans restaurer afin d’identifier plus rapidement les snapshots exploitables,
- Automatiser le redémarrage de l’activité via l’utilisation d’un orchestrateur interne.
*Pour plus d’informations sur le SDDC VMware Cloud on AWS, consultez notre livre blanc ici.
VCDR est une solution SaaS créée et maintenue par VMware qui permet aux clients de simplifier leurs scénarios de reprise d’activité dans le cloud.
Et finalement, VCDR, cela fonctionne comment ?
Le schéma suivant décrit le fonctionnement général de VCDR
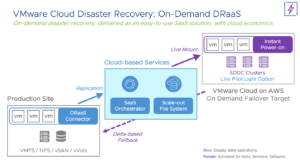
Les composants sont :
- Le site à protéger ou « Production Site »
- Le Cloud où sont sauvegardées les VMs à protéger ou « Backup Site »
- Enfin, le site où les VMs sont restaurées ou « Recovery SDDC »
- Le connecteur DRaaS est une Appliance virtuelle installée dans le « Production Site » où s’exécutent les VMs à protéger. Le connecteur DRaaS communique avec l’orchestrateur SaaS.
- L’orchestrateur SaaS est un composant cloud qui présente une interface utilisateur (UI) pour utiliser l’offre de services et inclut plusieurs capacités d’orchestration de reprise pour automatiser le processus de reprise après un sinistre. Il est situé dans le « Backup Site ».
- Scale-out File System (SCFS) est un composant cloud qui permet le stockage efficace des sauvegardes des VMs et permet à ces dernières d’être récupérées très rapidement via un processus de réhydratation efficace des données. Lui aussi est situé dans le « Backup Site ».
- Enfin le SDDC (VMC) lui est l’environnement VMware provisionné dans AWS qui vient recevoir les VMs restaurées en cas de désastre. Il se trouve dans le « Recovery Site »
VCDR une vraie solution « DRaaS on demand » ?
VCDR est l’une des rares solutions cloud du marché qui permet de ne pas disposer d’une infrastructure dormante, ce qui est d’un point de vue économique, relativement intéressant. En effet, lors du déclenchement d’un PRA, VCDR va provisionner de manière automatisée un SDDC VMware Cloud on AWS. Bien évidemment, les RPO/RTO doivent être compatibles avec ce mode de fonctionnement sinon il faut utiliser l’option « Pilot Light » pour exploiter un SDDC VMConAWS déjà déployé.
Macro-étapes à suivre en cas d’attaque
Si une société subit une attaque ransomware, il est capital d’identifier le point de rétention fiable à restaurer avant de lancer la reprise d’activité en utilisant VCDR.

Notre retour terrain
Les cas d’usage types auxquels VCDR répond sont nombreux. Nous allons présenter un scénario où l’activité du client est redémarrée dans le cloud en cas de compromission du système d’information local à travers l’utilisation d’un ransomware.
Les attaques ransomwares chiffrent les données qui empêchent les utilisateurs d’accéder à leurs données. Ces attaques créent de nombreux problèmes :
- Très peu d’outils de sécurité permettent de les contrer.
- Les attaques ciblent en priorité les données de sauvegarde empêchant ainsi toute reconstruction du SI,
- Ces attaques pénalisent fortement les activités d’une entreprise jusqu’à la mettre à l’arrêt complètement,
- Les assurances couvrent de moins en moins ce type de risques à cause de leurs coûts exorbitants et également dû à la probabilité du fort risque d’être touché,
- Il est difficile d’estimer la quantité de données volées et depuis quand l’exfiltration des données est en cours,
- Il est aujourd’hui impossible de garantir la fiabilité totale du système d’information contre ces menaces mais aussi de s’assurer que les pirates respecteront leurs engagements en cas de paiement de rançon.
Un exemple :
Nous avons eu l’occasion d’accompagner l’un de nos clients dans la construction de son PRA en se basant sur la solution VCDR puisqu’il ne souhaitait plus investir dans une salle dormante pour son PRA.
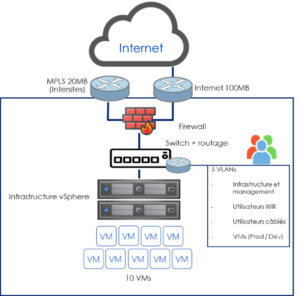
L’architecture on-premise VMware héberge plusieurs machines virtuelles avec l’utilisation de plusieurs VLAN. Les accès depuis l’extérieur sont protégés par un firewall périmétrique.
Architecture à protéger
Scénario de reprise d’activité
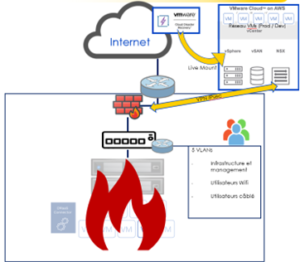
Quid de la reprise d’activité dans cette architecture ?
En cas de compromission, un SDDC VMware Cloud on AWS est provisionné à la demande en moins de 2h. En parallèle du déploiement, il est nécessaire d’identifier le point de rétention le plus fiable afin de pouvoir lancer le plan de démarrage des VMs. L’interconnexion est gérée via un tunnel IPSEC monté entre le FW on-premise et le SDCC VMware Cloud on AWS via NSX. Le routage est quant à lui modifié afin de permettre aux utilisateurs d’accéder aux VMs dans le cloud.
Rendez-vous dans notre prochain article afin de suivre les étapes nécessaires à la mise en place du service VCDR !
Louis PÉJAUDIER, Consultant Cloud et Virtualisation VMware
Avec le soutien rédactionnel de Maxime Guillotte, Tribu Leader VMware Rhône-Alpes & Léonardo Coscia, Tribu Leader VMware
