

L’AWS Summit Paris est organisé tous les ans et rassemble au Palais des Congrès avec près de 10000 personnes. L’occasion de prendre la température sur les nouvelles tendances et de paver le futur du cloud tout entier. Oui, rien que ça !
Sans surprise, l’IA monopolise la quasi-totalité de la keynote. A tel point qu’on se sentirait presque dépassé par les événements. Mistral AI, Anthropic, Hugging Face, Bedrock (enfin disponible à Paris d’ailleurs !), des interventions clients attestant de la puissance de l’IA au service de leur business. Le ton est clair, il ne faut pas rater le train. L’avantage ? Du développement d’un modèle jusqu’à son utilisation en production, AWS dispose d’un panel de services complet.
AWS investit massivement dans l’IA. C’est jusqu’à 4 milliards de dollars investis dans la start-up d’IA Anthropic. Une mise en avant massive était évidemment attendue mais le « wow factor » technique n’était pour moi pas au rendez-vous. Je n’y connais toujours pas grand-chose à l’IA, il va falloir y remédier…
Photo issue de la présentation de Mai-Lan Tomsen Bukovec VP of Technology AWS

Présentation de Mai-Lan Tomsen Bukovec VP of Technology AWS, 100% AI/Data
Les intervenants se succèdent et témoignent de deux choses : AWS permet d’une part aux modèles IA de se développer et de prospérer comme en ont attesté Arthur Mensch – CEO de Mistral AI, Thomas Wolf – Co-Founder de Hugging Face et Tom Brown – Co-Founder d’Anthropic, et d’autre part aux clients d’utiliser les modèles en production de manière à en faire profiter leur business. C’était le cas pour Raphaëlle Deflesselle – CTO de TF1 et Fabien Mangeant – Chief Data and AI Officer Air Liquide. Pour le coup on a eu le droit à un peu plus de concret avec les témoignages clients. La plateforme TF1+ utilise l’IA pour générer des suggestions de programmes adaptées à chacun. Air Liquide l’utilise pour faciliter l’approvisionnement des clients : des industries aux hôpitaux, les niveaux de gaz industriels sont surveillés via une foule de capteurs. Une fois les données remontées, l’IA est utilisée pour mobiliser la chaîne d’approvisionnement pour éviter la panne sèche.
Le Summit c’est la keynote mais aussi et surtout, les sessions ! C’est 150 sessions qui sont proposées tout au long de la journée. Voici celles que j’ai choisies :
- Découvrez les innovations en matière de souveraineté numérique sur AWS
- Résilience à l’échelle : les secrets d’Amazon
- Flux de données : Exploiter la puissance de Kinesis et Lambda
- Devops next level avec Amazon CodeCatalyst et l’IA Générative
La souveraineté numérique sur AWS
Par Nils Hansma, Yanis Lagsir, AWS
A l’heure où le « cloud » connaît une adoption croissante chez des fournisseurs majoritairement étrangers (pour ne pas dire nord-américains), la question de la souveraineté se pose naturellement. Mais c’est quoi en fait, la « souveraineté » ?
On parle de souveraineté à deux niveaux :
La souveraineté des données, et la souveraineté opérationnelle.
Les données sont souveraines car hébergées dans la région locale. Les données sont souveraines car il est garanti que l’opérateur ne dispose d’aucun accès aux données…
…sauf si la loi l’exige. C’est là que ça se complique. En hébergeant les données sur AWS en Europe, nous sommes soumis au RGPD, qui encadre de manière stricte la gestion des données personnelles européennes. Le Cloud Act américain autorise en théorie l’accès aux données des entreprises américaines et ce peu importe leur localisation mondiale, mais seulement sur une décision de justice liée à une enquête criminelle. Le Cloud Act précise par ailleurs la nécessité d’une entente bilatérale entre entités judiciaires américaines et européennes si besoin d’un accès aux données.
En pratique, il y a quand même un certain flou et des entreprises industrielles à fortes contraintes réglementaires peuvent exiger un contrôle total sur le chiffrement de leurs données. C’est là qu’interviennent le service AWS KMS (Key Management System) et le récent service XKS (External Key Store).
AWS se veut totalement transparent sur le sujet et propose une multitude de ressources pour en témoigner : https://aws.amazon.com/fr/compliance/digital-sovereignty/
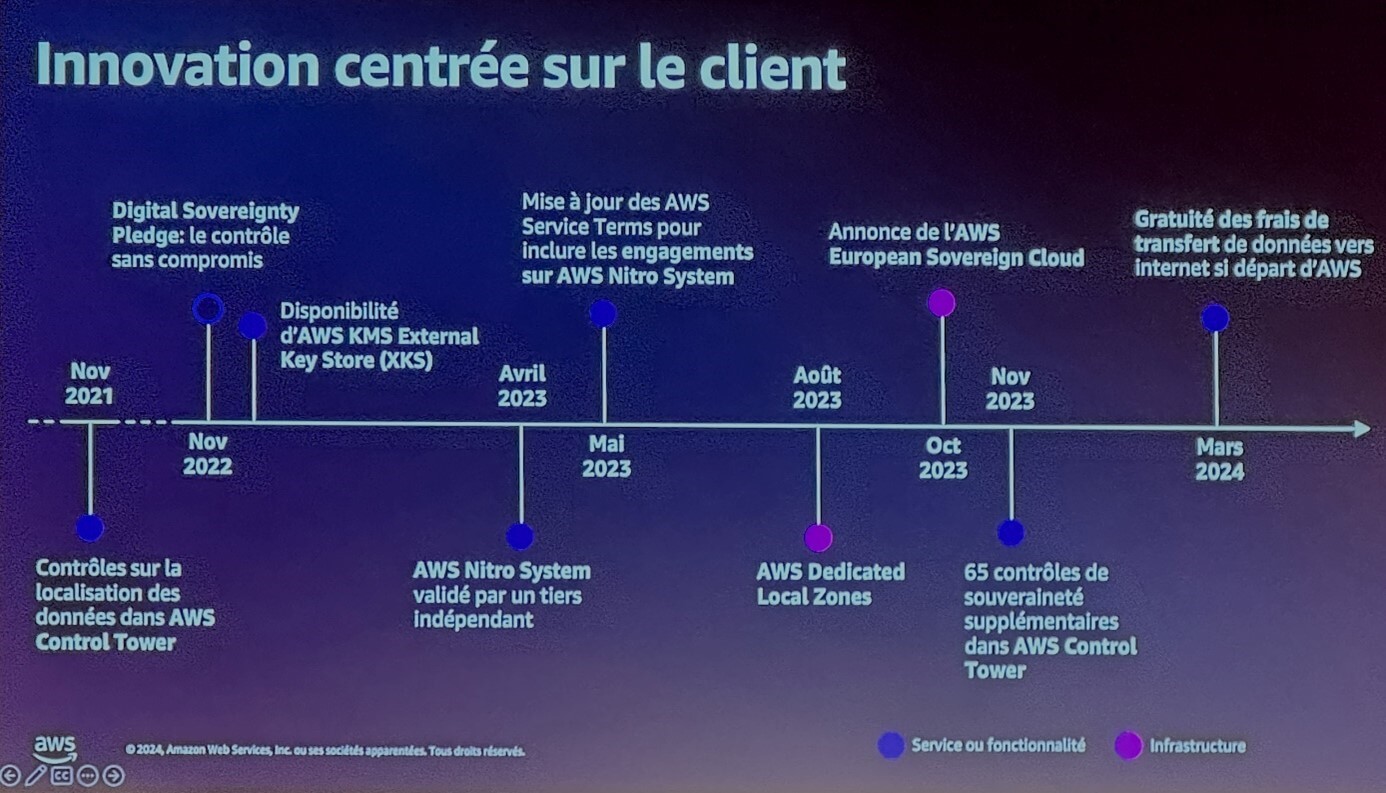
Slide tirée de la présentation de Nils Hansma & Yanis Lagsir, AWS
AWS permet un contrôle total sur les clés de chiffrement, quitte à utiliser des modules HSM (Hardware Security Modules) localisés dans les centres de données des clients. La responsabilité quant à la disponibilité du service incombe alors au client. Voir la documentation du service KMS.
Plusieurs solutions existent, il appartient au client de choisir le meilleur compromis entre contrôle et performances/disponibilité :
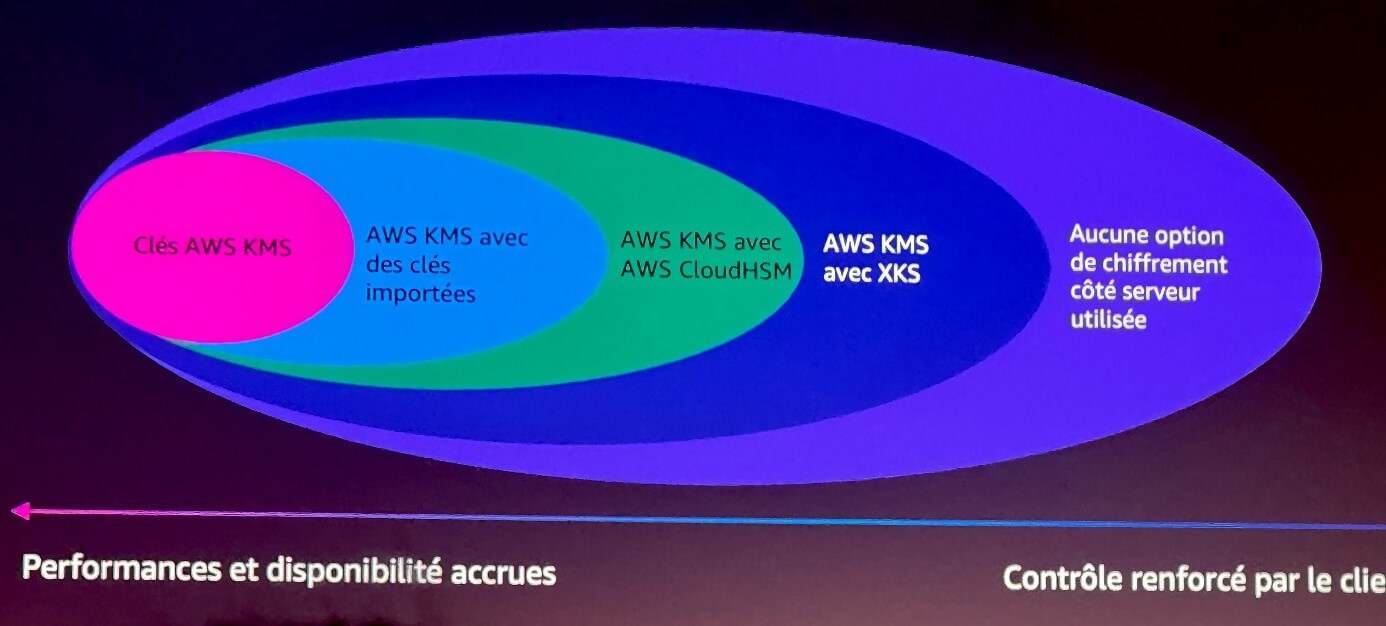
Au plus simple : j’utilise les clés KMS gérées par AWS. Cela ne veut pas dire que n’importe quel employé d’AWS a accès à mes données. Les clés ne sont pas stockées mais se trouvent dans la mémoire vive de module HSM certifiés FIPS 140-2. L’accès aux clés KMS est limité à mon compte selon les permissions que je définis.
Si je désire plus de contrôle, je peux importer mes propres clés. Si je veux en plus que mes clés vivent sur des modules HSM m’étant totalement dédiés, je peux utiliser le service AWS CloudHSM. Si je n’ai pas du tout envie d’avoir affaire à AWS pour mes clés, je les déporte sur des modules HSM dans mes centres de données.
Dernière option, je ne chiffre pas mes données au niveau du serveur, mais au niveau du client. Mes données sont déposées déjà chiffrées sur AWS.
AWS KMS (Key Management System) est un service incontournable d’AWS. Pour en savoir plus sur les guides de bonnes pratiques et les documents relatifs à la compliance, voir ce lien.
Résilience à l’échelle
Par Aurelia Pinhel, AWS & Florian Blond, AWS
Amazon a débuté par vendre des livres sur Internet. Puis l’entreprise s’est agrandie et s’est diversifiée. Le secteur du retail alterne entre périodes de très fortes sollicitations et périodes creuses. Comment font-ils pour s’assurer le fameux 99.999% de disponibilité ?
Plusieurs services pris en exemple : Prime Video, Amazon Music, et Ring, un service de sonnette connectée pour porte d’entrée.
Leur point commun ? Une architecture « cellulaire » :
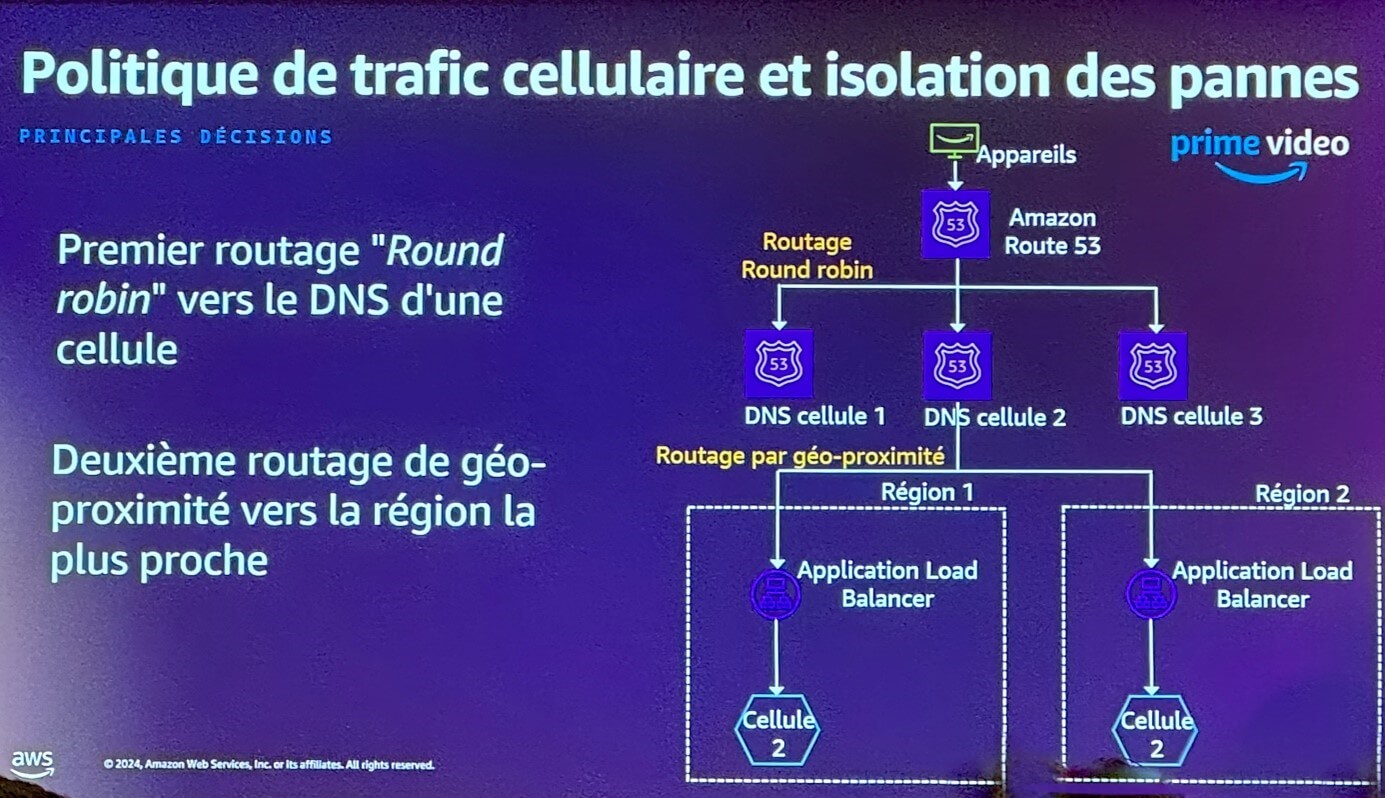
Slide tirée de la présentation d’Aurelia Pinhel & Florian Blond, AWS
Le principe est de découper l’application en plusieurs cellules afin de diviser le « blast radius » ou « rayon d’explosion » : ce terme matérialise l’impact qu’aurait une défaillance.
Le routage entre cellules est décidé par Route53, le service DNS d’AWS. L’utilisateur fait une requête sur « primevideo.com ». Route53 dispose d’une multitude de destinations possibles, plusieurs
« cellules ». Une cellule est sélectionnée un peu au hasard en Round Robin, puis au sein d’une cellule un second routage est fait pour privilégier une région proche de l’utilisateur.
Sur l’architecture présentée ci-dessus, une panne peut survenir sur un Application Load Balancer – un équilibreur de charge qui fait l’interface entre la requête et les ressources qui présentent les données. Dans ce cas, un health check Route53 permettrait de détecter une anomalie sur une cellule, de ne plus y router le trafic, et ainsi de préserver la qualité de service de manière invisible pour l’utilisateur.
L’exemple d’Amazon Music montre une strate supplémentaire, les « supercells », ou groupe de cellules :
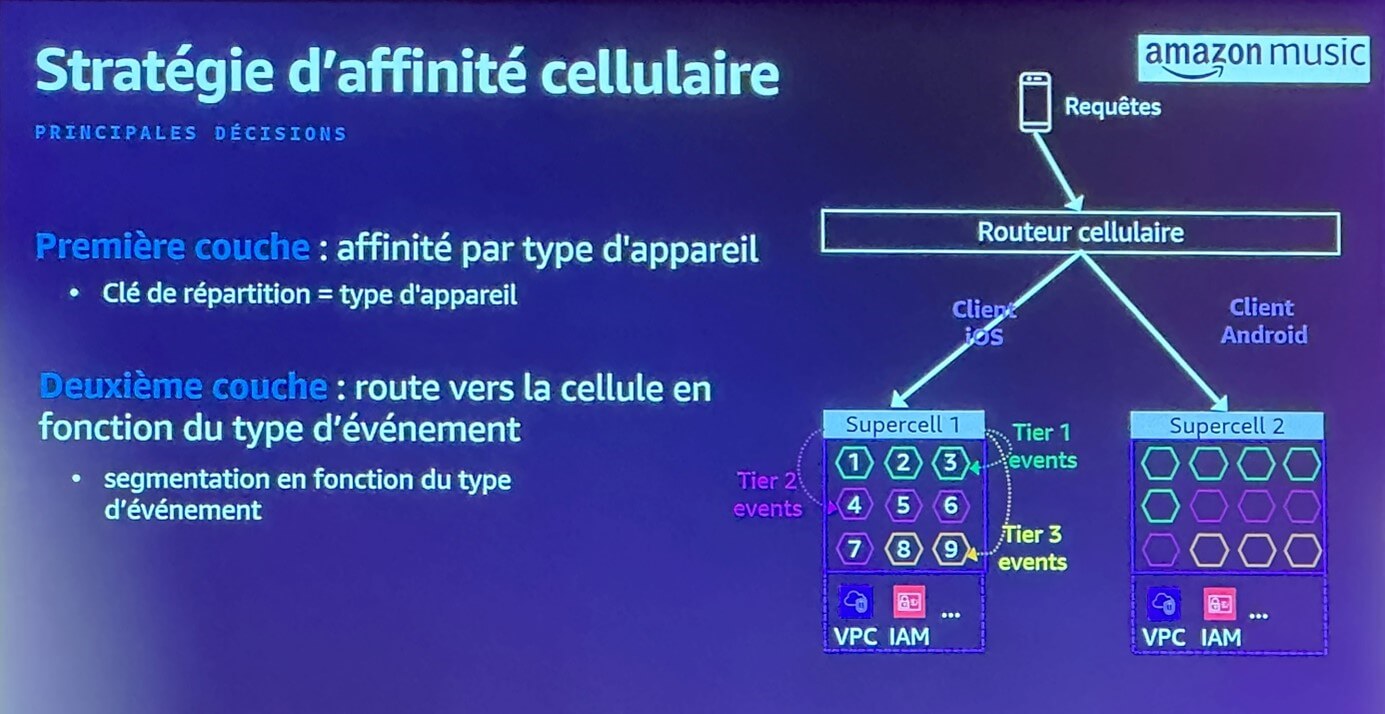
Les supercells sont réparties en fonction de la typologie du client – iOS ou Android.
Au sein d’une supercell, les cellules sont organisées en fonction de la criticité de l’événement à traiter – royalties, compte utilisateur, « like » sur une musique…
Une telle segmentation permet de limiter au maximum l’impact d’une panne, tout en priorisant leur résolution suivant leur criticité. Pas mal non ?
L’exemple du service Ring a ensuite été utilisé pour mettre en lumière les besoins en « scalabilité » (ou mise à l’échelle en bon français). Ring est un service de sonnette connectée. On imagine aisément que certaines périodes sont plus amenées à générer des évènements que d’autres. Sans possibilité d’adapter la taille de l’infrastructure de manière dynamique, on n’aurait pas d’autre choix que de la dimensionner pour le « pire » des scénarios pour encaisser la charge d’un jour dans l’année…C’est ni économique ni écologique !
Alors comment fait-on pour s’adapter au mieux au besoin à l’instant « t » ? Prenons le plus gros jour de l’année pour Ring. Quel jour de l’année met le plus à mal une sonnette de porte d’entrée ?
C’est Halloween !
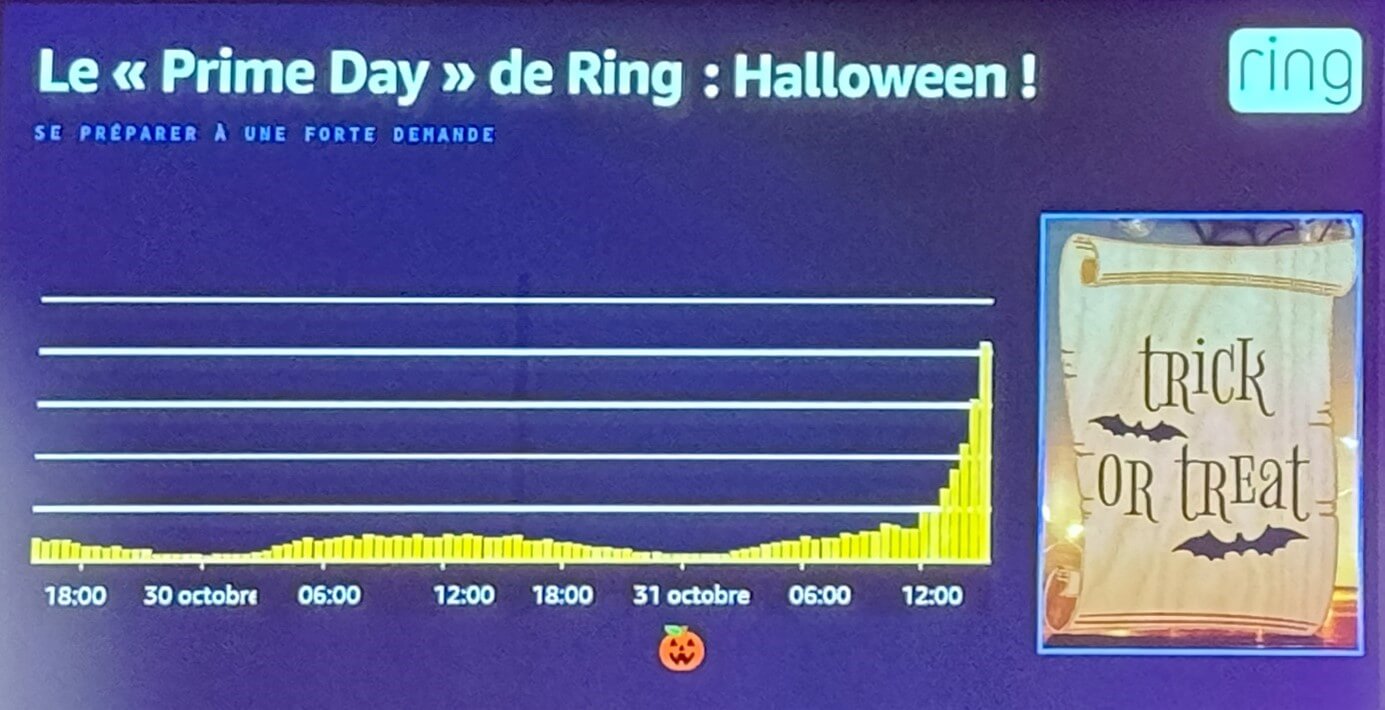
Et voici le secret tant attendu :
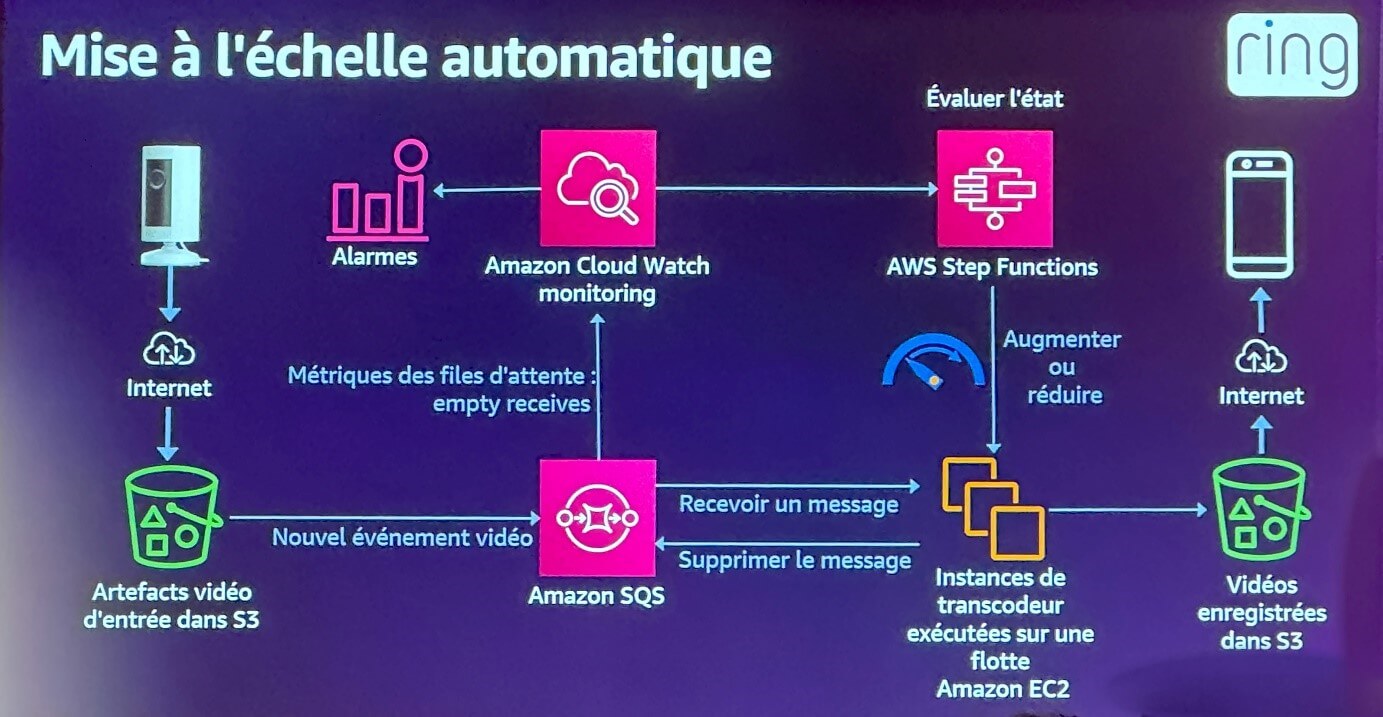
Principe :
- La sonnette dépose les fichiers vidéo dans un bucket S3 et déclenche un événement Eventbridge
- L’événement est transmis à une file SQS (Simple Queue Service)
- Cette file SQS est consommée de deux manières :
- Par les instances de transcodage pour traiter les vidéos et les stocker, pour qu’elles soient accessibles par l’utilisateur ;
- Par Cloudwatch, qui en analysant les métriques, sera à même de déterminer la charge courante. Si beaucoup de flux à traiter, on charge une Step Function d’aller déployer de nouvelles instances de transcodage. S’il n’y a plus grand-chose à traiter, on fait en sorte de diminuer le nombre d’instances pour réduire les coûts.
S’en est suivi une présentation de leur « Service Event Bus », ou SEB. Un moyen développé pour traiter les événements aussi rapidement que possible en découplant plusieurs niveaux :
- Le niveau de Service, qui expose l’API et est chargé du routage
- Le niveau data plane, qui s’interface entre data provider et data consumer via Amazon Managed Streaming for Apache Kafka (MSK)
- Le niveau consommation de données via des comptes « client » qui viennent consommer la donnée via une couche de proxy s’appuyant sur ECS (Elastic Container Service).
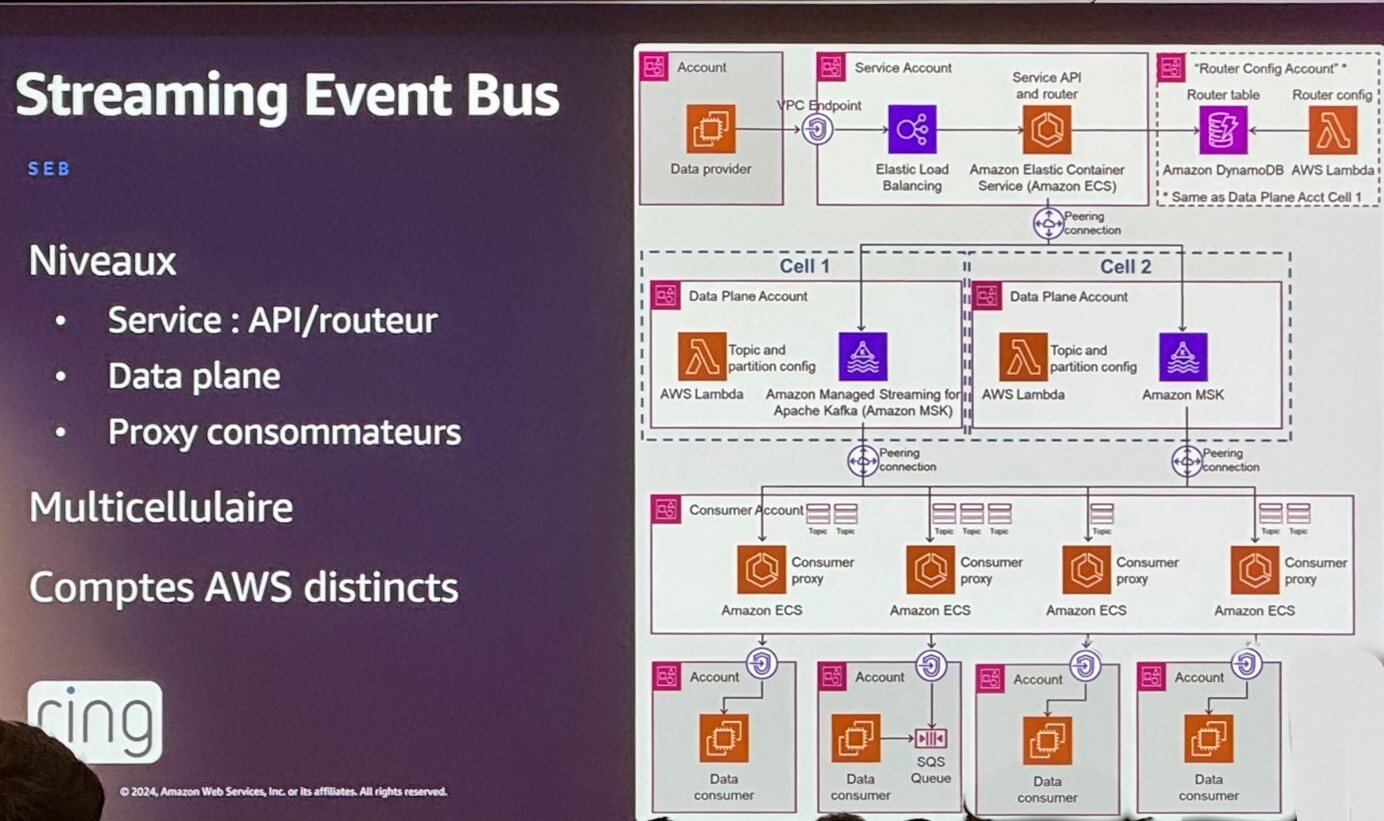
Outre les aspects de résilience et de performance, cette architecture permet d’obfusquer la configuration des nœuds MSK de la couche data plane pour les comptes consommateurs.
Si elle est rendue disponible sur le compte Youtube AWS, je vous invite à consulter la vidéo de la session où Aurelia Pinhel et Florian Blond expliquent très bien le système (et sûrement bien mieux que moi 😊)
Le résultat est sans appel, la disponibilité est au rendez-vous :

Pas une seule région sous les 99.9999% de disponibilité, et 100% même pour trois d’entre elles, impressionnant ! Et on n’a pas évoqué une seule fois EKS (Elastic Kubernetes Service), je dis ça comme ça…
Quelques liens pour aller plus loin, proposés en fin de session :
[Workshops]3 workshops L200 et L300 sur la resilience
[Whitepaper] Resilience Lifecycle Framework: Amélioration continue de la résilience
[Blog post] Ingénierie du chaos dans le cloud
Kinesis Data Streams vs Lambda
Par Cédric Pelvet, Alexis Gunst Horn, AWS
J’étais curieux d’assister à cette session car autant j’utilise énormément Lambda, autant Kinesis Data Streams…jamais. Peut-être qu’il pourrait répondre à un besoin que j’adressais jusqu’alors en « réinventant la roue ». C’est assez facile de passer à côté d’un service qui pourrait nous faciliter la vie, forcément avec plus de 200 services AWS disponibles…
Quand on parle de « streaming », on a deux populations : les services qui produisent la données – les producteurs, et ceux qui viennent consommer la données – les consommateurs. Entre les deux, un service qui permet d’ingérer le flot de données et de le rendre disponible pour les consommateurs. C’est à ça que sert Kinesis Data Streams
Exemple de producteurs :
- Amazon Cloudwatch : je produis des logs venant d’une fonction Lambda, d’une instance EC2…Et je veux les envoyer quelque part pour les traiter
- Amazon EventBridge : j’ai des évènements qui déclenchent une règle Eventbridge, et je veux envoyer ces évenements pour traitement
- AWS IoT Core : ma flotte d‘objets IoT font remonter des données de capteurs, et je veux ordonner tout ça
- Plus généralement une application bénéficiant d’un moyen de communiquer avec Kinesis via un SDK (Software Develoment Kit)
Exemple de consommateurs :
- Amazon Kinesis Firehose : j’envoie les données dans un S3, une base de données…Ou un partenaire comme Splunk ! Sans devoir gérer les joyeusetés de la « bufferisation » et de la transformation.
- Des services managés orientés Big Data : Apache Flink, Amazon EMR
- AWS Lambda ! On vient consommer les données depuis Kinesis Data Streams. Comment ne pas faire exploser le nombre d’exécutions concurrentes ?
Kinesis Data Streams utilise la notion de « shard », c’est l’unité de parallélisme. Un shard, c’est simplement 1Mo/s ou 1000 enregistrements par seconde en entrée.
En sortie, c’est 2Mo/s.
Côté Lambda, par défaut une instance viendra traiter un shard :
(pour ceux qui ne connaîtraient pas Lambda : c’est du Function as a Service ou FaaS, j’écris du code qui est exécuté dans un conteneur)
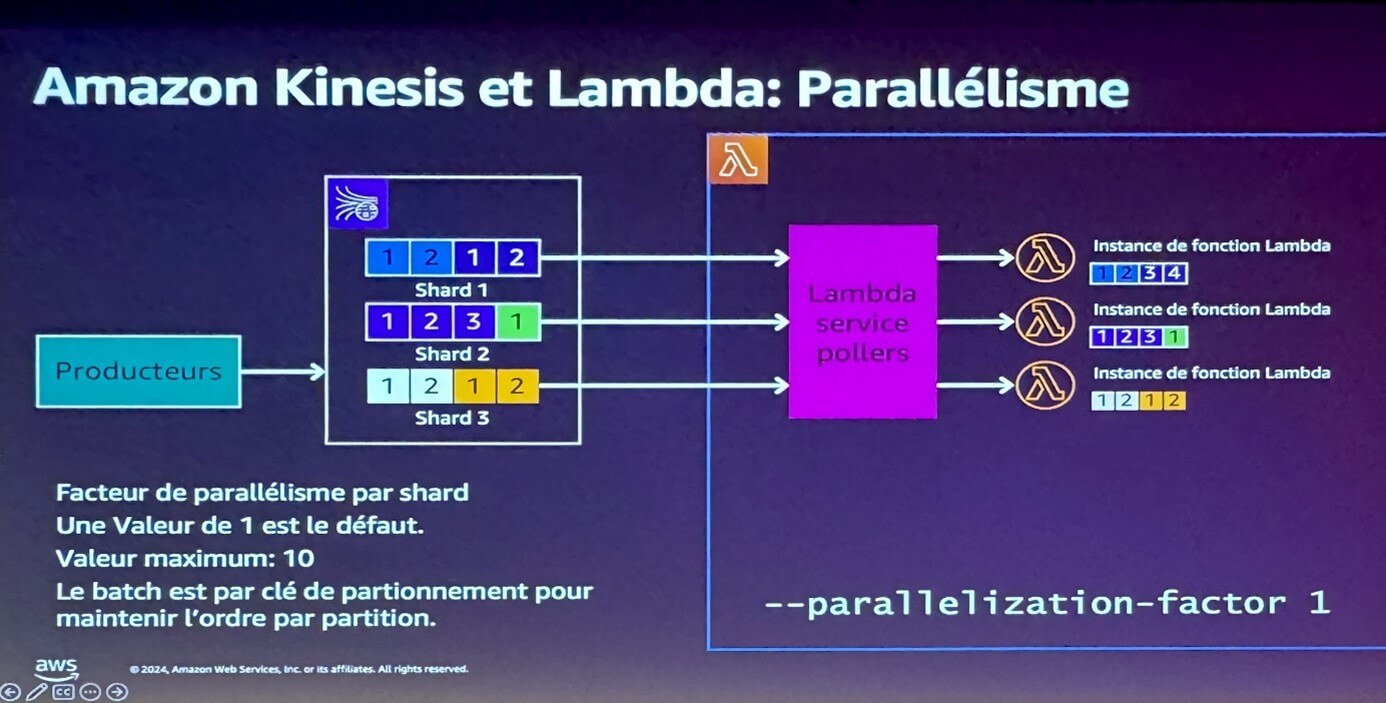
Petite erreur sur le slide : La première instance consomme bien tout ce qui est en entrée dans le Shard 1, à savoir 1212, par 1234.
Par défaut, une instance de Lambda consomme un shard.
Je pourrais dire : j’aimerais que mes shards soient traités en parallèle :
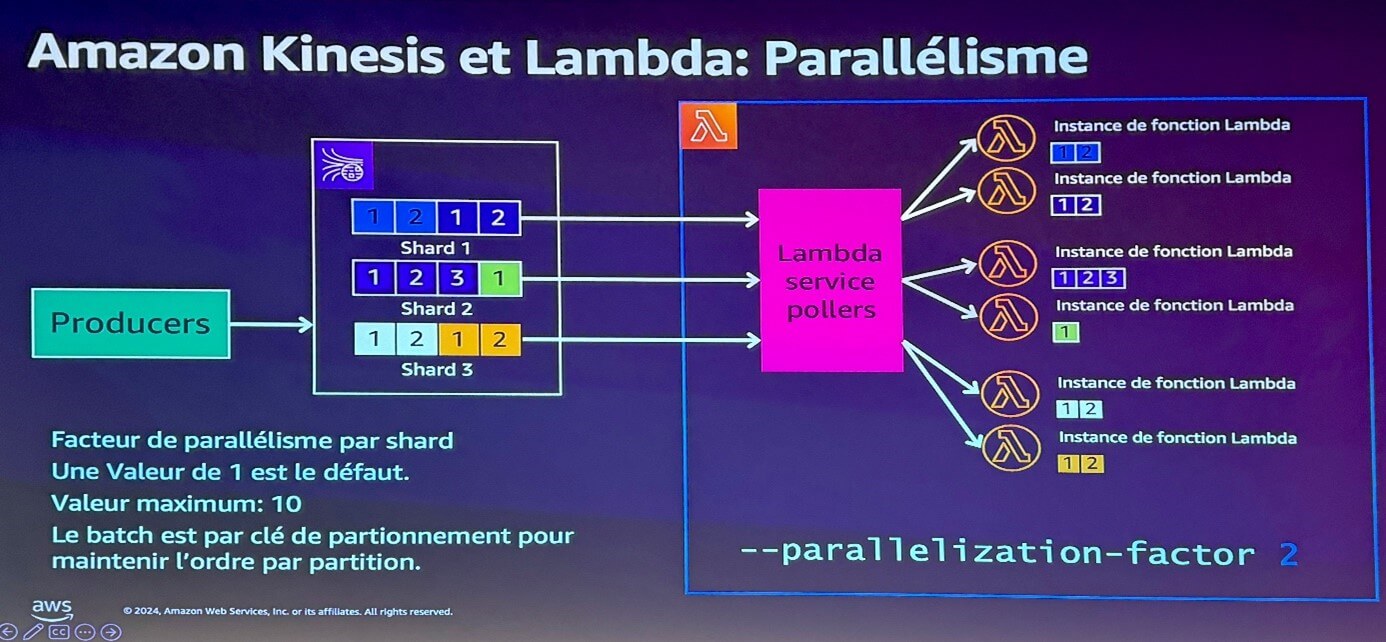
Dans ce cas, je découpe mon shard pour qu’il y ait systématiquement deux instances Lambda qui viennent le consommer. J’accélère donc mon traitement. Attention cependant à fournir assez de ressources à ma fonction Lambda : plusieurs instances tourneront dans le même conteneur et je dois disposer d’assez de ressources pour ne pas saturer ma Lambda.
D’autres options sont possibles pour permettre un traitement plus optimisé des données :

Quelques mots sur les sigles inconnus :
EFO (Enhanced Fan Out) : je fais en sorte de dédier la bande passante en sortie à 2Mo/sec en lecture, par stream (= par shard). Sans EFO, la bande passante est mutualisée parmi les consommateurs. Si j’ai 20 consommateurs pour un même stream, en shared fan-out chaque consommateur pourrait en théorie lire à 102ko/sec maximum. J’enlève cette restriction en passant en EFO et chaque consommateur peut lire mon stream à 2Mo/sec.
Avro/Protobuf : ce sont des méthodes de sérialisation de la donnée à l’instar de JSON, mais en bien plus performant. Protocol Buffers (protobuf) côté Google, et Avro côté Apache.
Devops next level avec Amazon CodeCatalyst et l’IA Générative
Par Marin Mouscadet & Laurent Delhomme, AWS

Dernier atelier sur un peu d’IA Générative, il en fallait bien un peu !
Service du jour : AWS CodeCatalyst. Service récent car lancé en avril 2023, son but est de remplacer votre Jira, Github, Jenkins, VSCode…bref, de centraliser toutes les actions du cycle de vie d’une application.
Dernier accélérateur : Amazon Q. Un assistant boosté à l’IA Générative qui s’invite dans CodeCatalyst :
Concrètement ? Je crée une Pull Request dans laquelle je précise le plus complètement possible les actions que j’aimerais effectuer sur mon code. Cela peut aller de l’écriture de la documentation à la correction d’un bug du code.
Les démonstrations ont été assez simples : générer un README, et corriger un problème sur du vue.js :
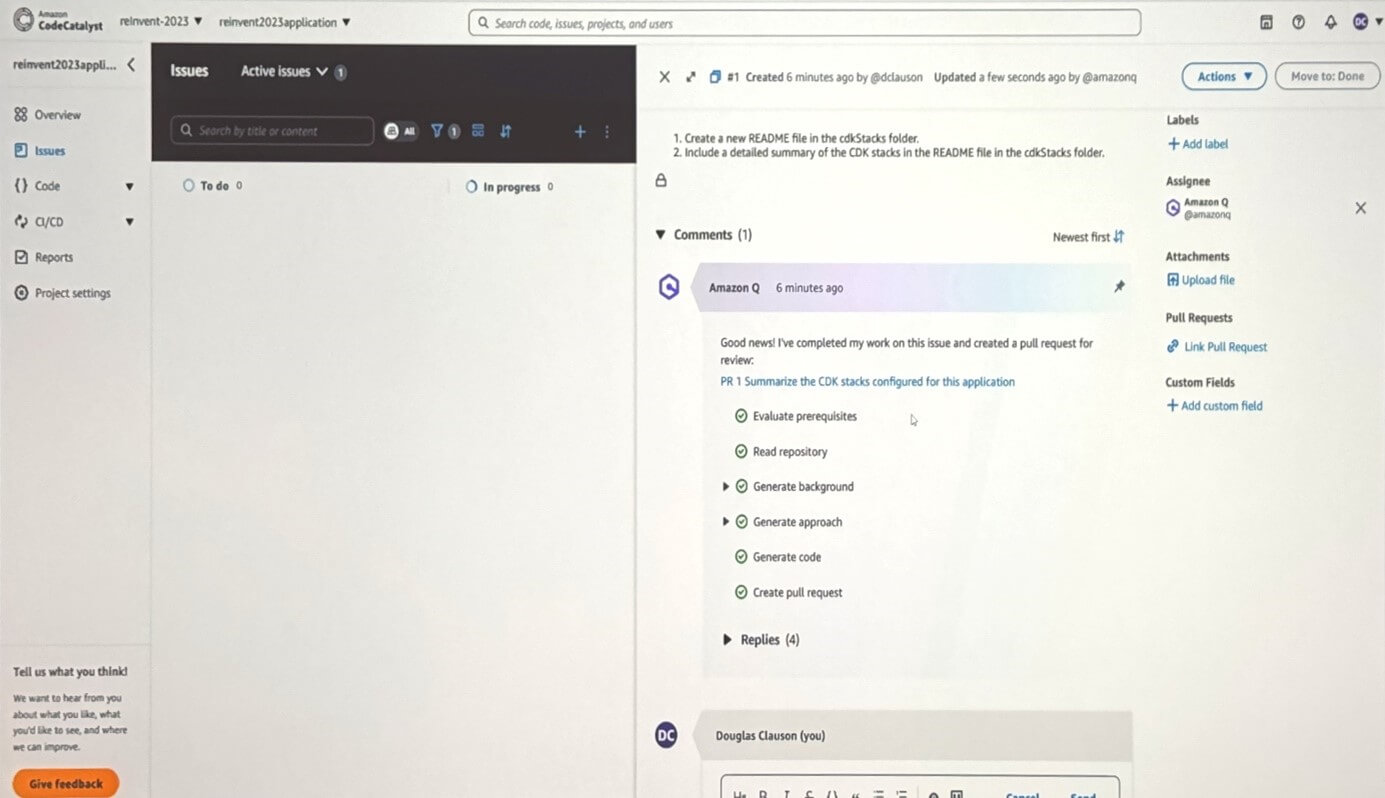
Ici on a le résultat d’une Pull Request demandant de la documentation. Q détaille les différentes étapes avant de livrer son résultat.
De l’aveu des présentateurs, l’outil est plus à l’aise sur de la génération de documentation que sur de la génération de code. Forcément, le code a été écrit dans un certain contexte avec des dépendances pas forcément accessibles par Q. Sur un bug simple, une demande ciblée à l’IA de votre choix avec le message d’erreur et un bout de code sera plus efficace. La précision de la réponse dépend de la précision de la question.
Côté timing, les exemples donnés étaient bouclés en 6 minutes environ. C’est à la fois rapide si tout est parfait dès la première itération, mais 10 aller-retours prendraient minimum une heure…L’intérêt paraît limité – pour l’instant en tout cas. On imagine que l’outil progressera avec le temps. En attendant, je garde mon GitHub Copilot qui est un allié de taille lorsqu’un problème demande une prise de recul. C’est un peu le collègue à la machine à café qui vous donne une réponse approximative mais suffisamment pertinente pour changer d’angle de vue et attaquer le problème différemment.
Conclusion
Comme l’a dit Julien Groues – AWS General Manager Europe South at AWS, l’IA est la partie émergée de l’iceberg, celle dont tout le monde parle. Il n’en reste pas moins les 90% d’infrastructures restantes pour lesquels des compétences à la fois très variées et spécialisées sont requises. L’AWS Summit est l’occasion d’aller voir comment font les copains, et d’aller jeter un coup d’œil à des sujets encore inconnus. La vraie force du cloud fait que finalement, il suffit de quelques clics sur un service pour commencer à expérimenter et monter en compétences.
Je n’ai pas spécialement parlé de GreenOps mais c’est toujours une préoccupation de tous les instants pour AWS et les partenaires. Objectif : 100% d’utilisation d’énergies renouvelables pour ses centres de données d’ici 2025. Ce qui apparaît un peu antinomique compte tenu des investissements faits en termes d’IA – très consommateurs de ressources. Les modèles d’IA tendent à l’efficience et c’est très bien, mais le meilleur moyen de préserver les ressources, c’est de ne pas en consommer ! Ne pas utiliser l’IA à outrance par effet de mode mais pour un réel besoin. Garder à l’esprit les 5 piliers du « well architected framework » d’AWS, parmi eux l’optimisation des coûts et la durabilité.
Serge SERBILADZE, Consultant Cloud, Réseau et Automatisation




