

Cloud Endure Disaster Recovery est (presque) mort ! Vive AWS Elastic Disaster Recovery !
Fin 2021, AWS a annoncé la disponibilité de « AWS Elastic Disaster Recovery ». Fortement inspiré de « CloudEndure Disaster Recovery », ce nouveau service offre une meilleure intégration dans l’écosystème des services AWS ainsi que dans la console d’administration AWS.
Au regard des faibles différences entre les solutions, on peut, sans risque, présumer que « AWS Elastic Disaster Recovery » continuera d’évoluer pendant que « CloudEndure Disaster Recovery » sera petit à petit déprécié.
Il est donc temps d’évaluer ce nouveau service !
Un cas d’usage en mode hybride
De nombreux clients de Metanext utilisent AWS comme extension de leurs centres de données privés. J’ai donc choisi un cas d’évaluation contraignant : la mise en place de la reprise d’activité d’un serveur dans un environnement complètement privé, autrement dit, sans accès Internet.
Disons-le tout de suite, ce cas d’usage n’est pas très bien documenté par AWS et nul doute que cet article fera gagner un peu de temps à tous ceux qui y seront confrontés.
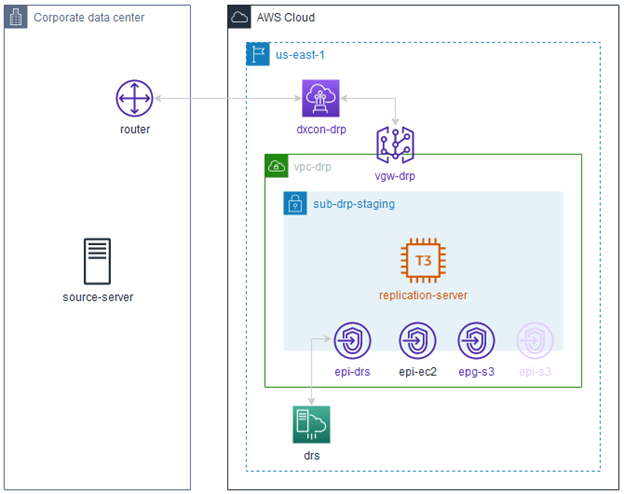
Pour éviter que cet article soit trop long et qu’il décrive des opérations qui ne sont pas au cœur du propos, je suppose que la structure désirant mettre en place la reprise d’activité d’un de ses serveurs dispose déjà d’une interconnexion correctement routée entre son propre centre de données privé et un VPC AWS.
Tout d’abord, le VPC…
Ce VPC n’a évidemment aucune Internet Gateway qui lui est attachée et sera nommé dans cet article vpc-drp. Son identifiant est vpc-0123456789abcdefg
Dans le même esprit, on conçoit que vpc-drp héberge un subnet forcément privé, nommé sub-drp-staging, identifié par subnet-1234567890zyxwvut et dont la table de routage est rtb-0123456789abcdefg
Tout est maintenant en place pour que je puisse mettre en œuvre cette reprise d’activité en cas d’incident.
Au tour de AWS Elastic Disaster Recovery…
Commençons par paramétrer en mode privé l’« AWS Elastic Disaster Recovery » en utilisant « AWS CloudShell » :
SUBNET_ID=subnet-1234567890zyxwvut aws drs create-replication-configuration-template \ --associate-default-security-group \ --bandwidth-throttling 0 \ --no-create-public-ip \ --data-plane-routing PRIVATE_IP \ --default-large-staging-disk-type GP3 \ --ebs-encryption DEFAULT \ --pit-policy enabled=true,interval=10,retentionDuration=60,ruleID=1,units=MINUTE \ --replication-server-instance-type t3.small \ --replication-servers-security-groups-ids \ --staging-area-subnet-id $SUBNET_ID \ --staging-area-tags {} \ --no-use-dedicated-replication-server
Ensuite, afin de pouvoir communiquer avec les services « publics » d’AWS, je vais devoir définir des « endpoints » accessibles depuis mon subnet sub-drp-staging :
- epi-drs: endpoint de type interface à destination du service « AWS Elastic Disaster Recovery »
- epi-ec2: endpoint de type interface à destination du service « EC2 » permettant de réaliser des snapshots et de lancer des instances de récupération
- epi-s3: endpoint de type interface à destination du service « S3 » qui sera utilisé par le source-server afin d’installer l’agent de réplication
- epg-s3: endpoint de type gateway à destination du service « S3 » qui sera utilisé par le replication-server lors de son initialisation
Le script ci-dessous permet de créer ces différents « endpoints ».
Je vais penser à noter (copier) les noms DNS résultant de la création des « endpoints » de type interface : ils me serviront pour l’installation de l’agent de réplication sur le source-server.
VPC_ID=vpc-0123456789abcdefg SUBNET_ID=subnet-1234567890zyxwvut RTB_ID=rtb-0123456789abcdefg # create security group for endpoints SG_ID=$(aws ec2 create-security-group \ --group-name sgr-vpce \ --description "Allow HTTPS to endpoints" \ --vpc-id $VPC_ID \ --query 'GroupId' \ --output text) aws ec2 authorize-security-group-ingress \ --group-id $SG_ID \ --protocol tcp \ --port 443 \ --cidr 0.0.0.0/0 # create endpoints aws ec2 create-vpc-endpoint \ --service-name com.amazonaws.us-east-1.drs \ --vpc-endpoint-type Interface \ --vpc-id $VPC_ID \ --subnet-id $SUBNET_ID \ --security-group-id $SG_ID \ --private-dns-enabled \ --tag-specifications ResourceType=vpc-endpoint,Tags=[\{Key=Name,Value=epi-drs\}] \ --query 'VpcEndpoint.DnsEntries[0].DnsName' \ --output text aws ec2 create-vpc-endpoint \ --service-name com.amazonaws.us-east-1.ec2 \ --vpc-endpoint-type Interface \ --vpc-id $VPC_ID \ --subnet-id $SUBNET_ID \ --security-group-id $SG_ID \ --private-dns-enabled \ --tag-specifications ResourceType=vpc-endpoint,Tags=[\{Key=Name,Value=epi-ec2\}] \ --query 'VpcEndpoint.DnsEntries[0].DnsName' \ --output text aws ec2 create-vpc-endpoint \ --service-name com.amazonaws.us-east-1.s3 \ --vpc-endpoint-type Interface \ --vpc-id $VPC_ID \ --subnet-id $SUBNET_ID \ --security-group-id $SG_ID \ --no-private-dns-enabled \ --tag-specifications ResourceType=vpc-endpoint,Tags=[\{Key=Name,Value=epi-s3\}] \ --query 'VpcEndpoint.DnsEntries[0].DnsName' \ --output text aws ec2 create-vpc-endpoint \ --service-name com.amazonaws.us-east-1.s3 \ --vpc-endpoint-type Gateway \ --vpc-id $VPC_ID \ --route-table-ids $RTB_ID \ --tag-specifications ResourceType=vpc-endpoint,Tags=[\{Key=Name,Value=epg-s3\}]
Sans oublier l’agent de réplication…
Les canaux de communication avec les services « publics » d’AWS étant, maintenant, ouverts, je peux passer à l’installation de l’agent de réplication sur mon source-server.
Afin d’utiliser des services AWS, cet agent devra disposer de privilèges lui permettant d’y accéder.
Etant loin d’être un fan des clés d’accès programmatique permanentes pour lesquelles on oublie très souvent de réaliser des rotations, je vais plutôt utiliser des clés temporaires puisque « AWS Elastic Disaster Recovery » le permet.
Pour cela, je crée un IAM role, lui attache la stratégie AWSElasticDisasterRecoveryAgentInstallationPolicy et demande à STS de me fournir des clés temporaires. J’ai donc une heure (délai d’expiration du token) ensuite pour installer l’agent 😉
ACCOUNT_ID=$(aws sts get-caller-identity \
--query 'Account' \
--output text)
cat > /tmp/local.json << EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::$ACCOUNT_ID:root"
},
"Action": "sts:AssumeRole"
}
]
}
EOF
ARN=$(aws iam create-role \
--role-name drs-agent \
--assume-role-policy-document file:///tmp/local.json \
--query 'Role.Arn' \
--output text)
aws iam attach-role-policy \
--role-name drs-agent \
--policy-arn arn:aws:iam::aws:policy/AWSElasticDisasterRecoveryAgentInstallationPolicy
aws sts assume-role \
--role-arn $ARN \
--role-session drs-agent
Encore un petit effort…
Pour l’installation de l’agent lui-même, je considère que mon source-server est un Linux.
Cependant, ce qui suit peut facilement être adapté à Windows en utilisant la documentation AWS.
Je vais donc commencer par télécharger le script d’installation en me connectant en SSH sur mon source-server et en utilisant le nom DNS fourni lors de la création de epi-s3 en pensant à remplacer l’étoile (*) par « bucket »
Ce nom DNS est en réalité un nom public résolu par Route 53 en une adresse privée.
En conséquence, mon script d’installation sera récupéré sur un bucket S3 public mais en passant par l’interconnexion du centre de données et mon VPC hébergé en us-east-1.
Pour que cela fonctionne, il suffit que le(s) serveur(s) DNS paramétré sur mon source-server soi(en)t capable(s) de forwarder une requête DNS vers des resolvers publics.
wget -O ./aws-replication-installer-init.py --no-check-certificate \
https://bucket.vpce-xxxxxxxxxxxxxxxxx-xxxxxxx.s3.us-east-1.vpce.amazonaws.com\
/aws-elastic-disaster-recovery-us-east-1/latest/linux/aws-replication-installer-init.py
Une fois le script téléchargé sur mon source-server, je peux l’exécuter en spécifiant les noms DNS des 2 « endpoints » de type interface :
sudo python3 aws-replication-installer-init.py \ --region us-east-1 \ --s3-endpoint bucket.vpce-xxxxxxxxxxxxxxxxx-xxxxxxx.s3.us-east-1.vpce.amazonaws.com \ --endpoint vpce- xxxxxxxxxxxxxxxxx-xxxxxxx.drs.us-east-1.vpce.amazonaws.com
Une fois lancé, le script demande les clés d’accès qui vont lui permettre de communiquer avec « AWS Elastic Disaster Recovery ». Il suffit alors de lui communiquer les clés que STS m’a fournies précédemment.
C’est beau une réplication en pleine action !
Après quelques minutes d’installation, la réplication commence et le script me fournit un source server ID de type s-0123456789abcdefg
Je peux alors suivre la progression de la réplication dans « AWS CloudShell » à l’aide de la commande suivante :
aws drs describe-source-servers \
--filters sourceServerIDs=s-0123456789abcdefg \
--query 'items[0].dataReplicationInfo.dataReplicationState' \
--output text
Résultat :
INITIAL_SYNC
Quelques minutes plus tard, la réplication initiale est achevée.
aws drs describe-source-servers \
--filters sourceServerIDs=s-0123456789abcdefg \
--query 'items[0].dataReplicationInfo.dataReplicationState' \
--output text
Résultat :
CONTINUOUS
À partir de là, si je veux faire un peu d’économies, je peux supprimer le endpoint S3 de type interface, epi-s3, car il ne sera plus utilisé.
Il reste encore un peu de travail
Bien sûr, une procédure de reprise sur sinistre ne se limite pas à l’installation d’un agent.
Il faut tester régulièrement les instances de restauration, vérifier la cohérence des données répliquées, confirmer que le temps de reprise est conforme au RTO attendu et enfin que la procédure de « Failback » est opérationnelle après le retour à un fonctionnement nominal du site principal.
Je ne décrirai ces parties du processus de reprise qui sont, somme toute, classiques et qui n’ont aucune spécificité au regard du cas d’évaluation exposé ici : le mode « privé ».
Et pour finir, les pré-requis en quelques mots
En conclusion, pour mettre en place « AWS Elastic Disaster Recovery » en mode privé j’aurais besoin, au préalable, de :
- 4 endpoints vers les services AWS accessibles à partir de mon subnet de staging privé
- Clés d’accès temporaires avec les privilèges nécessaires pour accéder aux services AWS
- Vérifier la résolution DNS publique des endpoints privés à partir de mes serveurs sources
Par Christophe ANNEREAU, Consultant Cloud & Tribu Leader


