
Screen scraping, cékoidon ?
Dans le contexte des réseaux informatiques, le screen scraping est une technique par laquelle un programme récupère des données à partir des équipement réseau afin d’y extraire des informations utiles.
Parmi les solutions qui permettent de faire du screen scraping (ou data scraping), “Netmiko” occupe une place privilégiée.
Netmiko
Netmiko est une bibliothèque en python développée par Kirk Byers, basée sur Paramiko.
Elle implémente une connexion SSH afin qu’elle soit utilisable pour l’automatisation réseau.
Netmiko fait en sorte de désactiver la pagination en output lorsque nous envoyons par exemple la commande “show run” afin d’avoir l’output en entier.
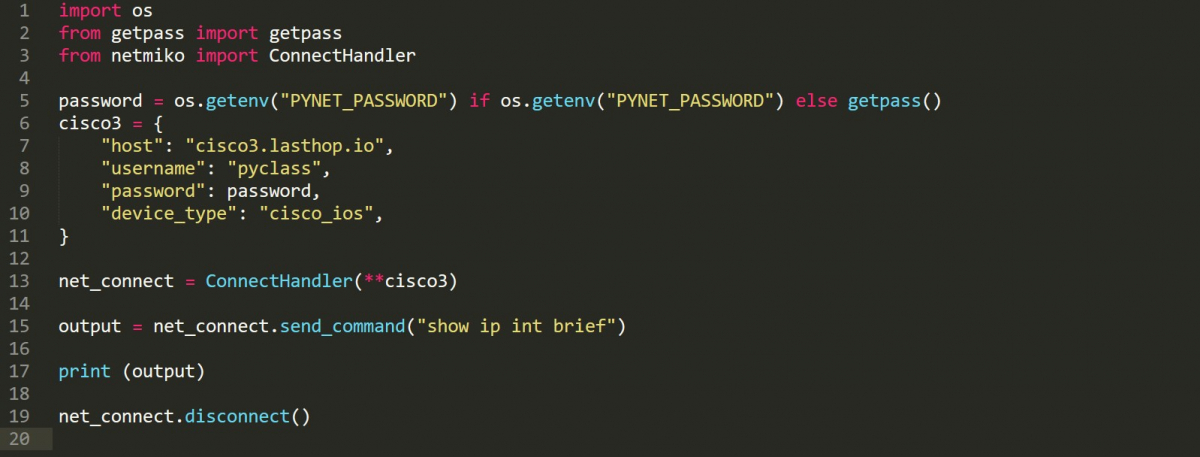
L’écho de la commande envoyée ainsi que le prompt “hostname#” ne sont pas inclus dans l’output. Netmiko capture seulement l’output du “show”.

Tout d’abord, un peu de Screen Scraping…
Imaginons un scénario courant où nous devons nous connecter à un équipement réseau et nous assurer que toutes ses interfaces sont dans un état up.
Pour les ingénieurs réseau “humains” connectés à l’équipement Cisco NX-OS, il suffit simplement d’exécuter la commande “show ip interface brief” sur le terminal pour savoir facilement à partir de l’output quelle interface est active (UP) :
nx-osv-2# show ip int brief IP Interface Status for VRF "default"(1) Interface IP Address Interface Status Lo0 192.168.0.2 protocol-up/link-up/admin-up Eth2/1 10.0.0.6 protocol-up/link-up/admin-up nx-osv-2#
Le Screen Scraping, une souffrance pour l’automatisation
Le saut de ligne, les espaces blancs et la première ligne du titre de la colonne se distinguent facilement à l’œil.
En fait, ils sont là pour nous aider à aligner, disons, les adresses IP de chaque interface de la ligne 1 à la ligne 2 et 3.
Si nous nous mettons à la place de l’ordinateur, tous ces espaces et sauts de ligne nous « éloignent » de l’output vraiment important, à savoir : quelles sont les interfaces à l’état UP ?
Pour illustrer ce point, regardons l’output généré par Netmiko pour la même opération :
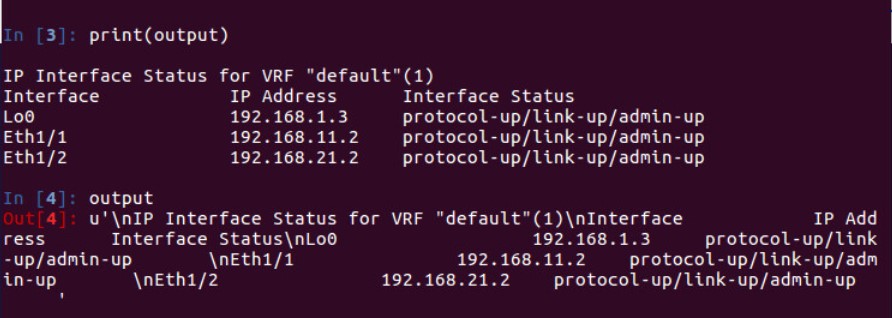
Si nous devions analyser les données contenues dans la variable « output », voici ce que je ferais d’une manière pseudo-code pour extraire uniquement l’information utile :
- Diviser chaque ligne via le saut de ligne.
- Retirer tout jusqu’au “VRF “default” (1)” et l’enregistrer dans une variable car nous voulons savoir quel VRF l’output affiche.
- Pour le reste des lignes (car nous ne savons pas combien d’interfaces existent), nous utiliserons une instruction d’expression régulière pour rechercher si la ligne commence par des noms d’interface, tels que « lo » pour le loopback et « Eth » pour les interfaces Ethernet.
- Nous devrons diviser cette ligne en trois sections séparées par un espace, comprenant respectivement le nom de l’interface, l’adresse IP et l’état de l’interface.
- Le statut de l’interface sera ensuite divisé en utilisant la barre oblique (/) pour nous donner le protocole, le lien et le statut d’administrateur séparément.
Ouf, cela fait beaucoup de travail juste pour obtenir un résultat qu’un être humain distingue en un coup d’œil !
Vous pourrez certainement optimiser ce pseudo-code et réduire le nombre de lignes dans le code, mais en général, ces étapes sont incontournables lorsque nous devons filtrer des outputs non structurés.
Il existe de nombreux inconvénients à cette méthode, mais les principaux problèmes que j’identifie sont répertoriés comme suit :
- Il n’y a absolument aucune garantie que l’output reste la même entre les différentes versions d’OS. Si l’output est légèrement modifiée, cela pourrait simplement rendre inutile notre bataille acharnée de collecte d’informations utiles.
- Nous passons beaucoup de temps sur les détails minutieux pour analyser les outputs de chaque commande. Il est difficile d’imaginer comment nous pourrions le faire pour les centaines de commandes que nous exécutons généralement.
- Les outils que nous utilisons pour faire le screen scraping ne comprennent généralement pas les commandes envoyées aux équipements réseau. Cela nous empêche de savoir si la commande envoyée a été exécutée avec succès;
Et maintenant au tour de l’API …
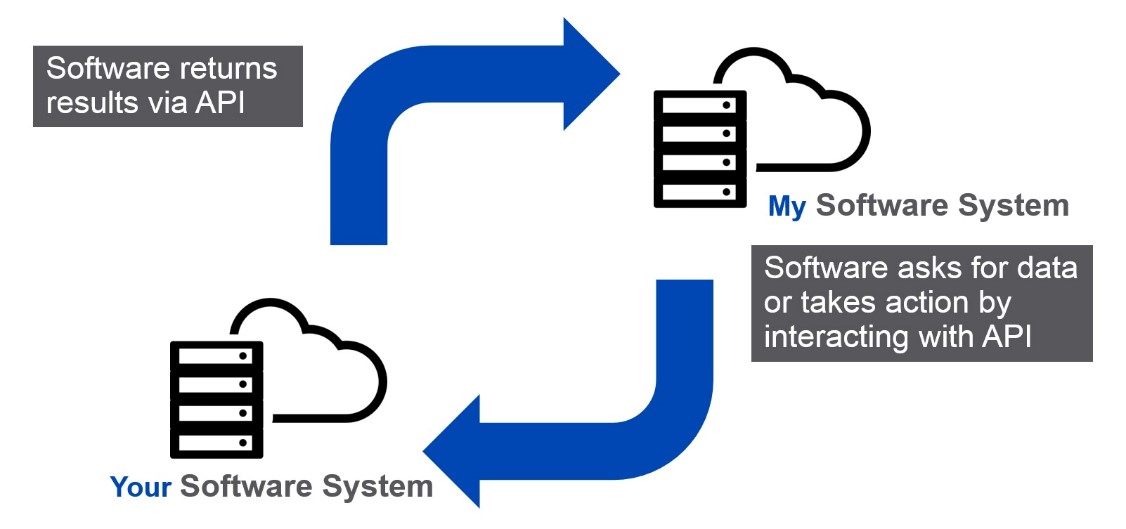
Une API (Application Programming Interface) est une Interface Applicative de Programmation qui permet d’établir des connexions entre plusieurs logiciels pour échanger des données.
Pensez aux différentes façons d’interagir avec le logiciel : vous pouvez ouvrir une interface Web pour accéder à votre messagerie. Vous pouvez avoir un workflow spécifique pour ouvrir des messages et les classer pour plus tard.
Chacun de ces workflows possède une « interface » ou une manière distincte de réaliser une tâche particulière.
Une API est similaire dans son concept. Au lieu d’interfaces humaines avec le logiciel, le logiciel s’interface avec le logiciel.
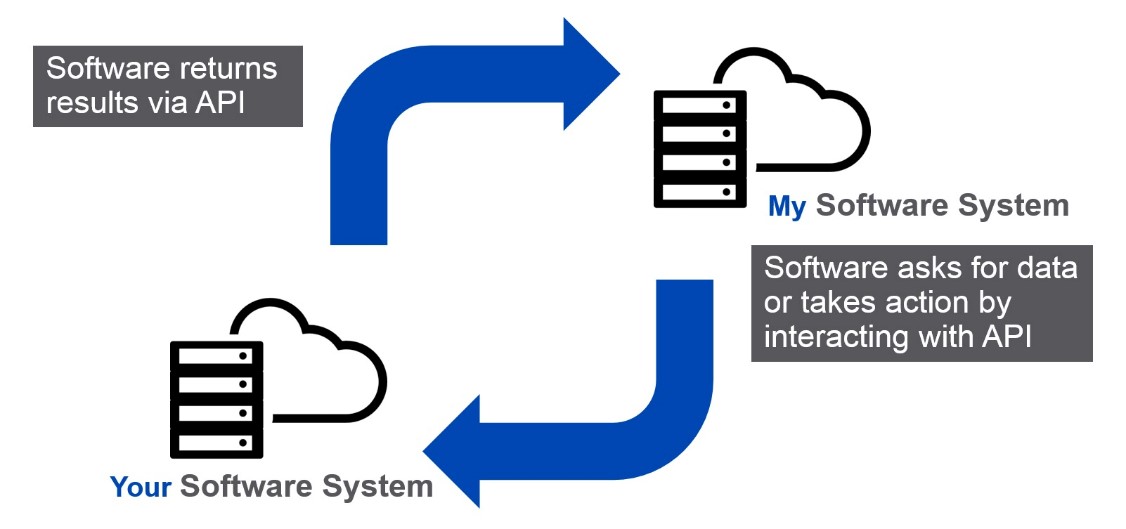
Afin d’illustrer l’avantage d’utiliser des APIs au lieu du Screen Scraping, nous prenons comme exemple l’NX-API qui est une API disponible sur la plateforme Cisco Nexus.
Le but est de comparer l’output de l’API NX-API à l’output du Screen Scraping précédent pour la même commande “show ip interface brief”. Dans notre exemple, nous manipulons l’API NX-API par le biais d’une bibliothèque Python (requests):
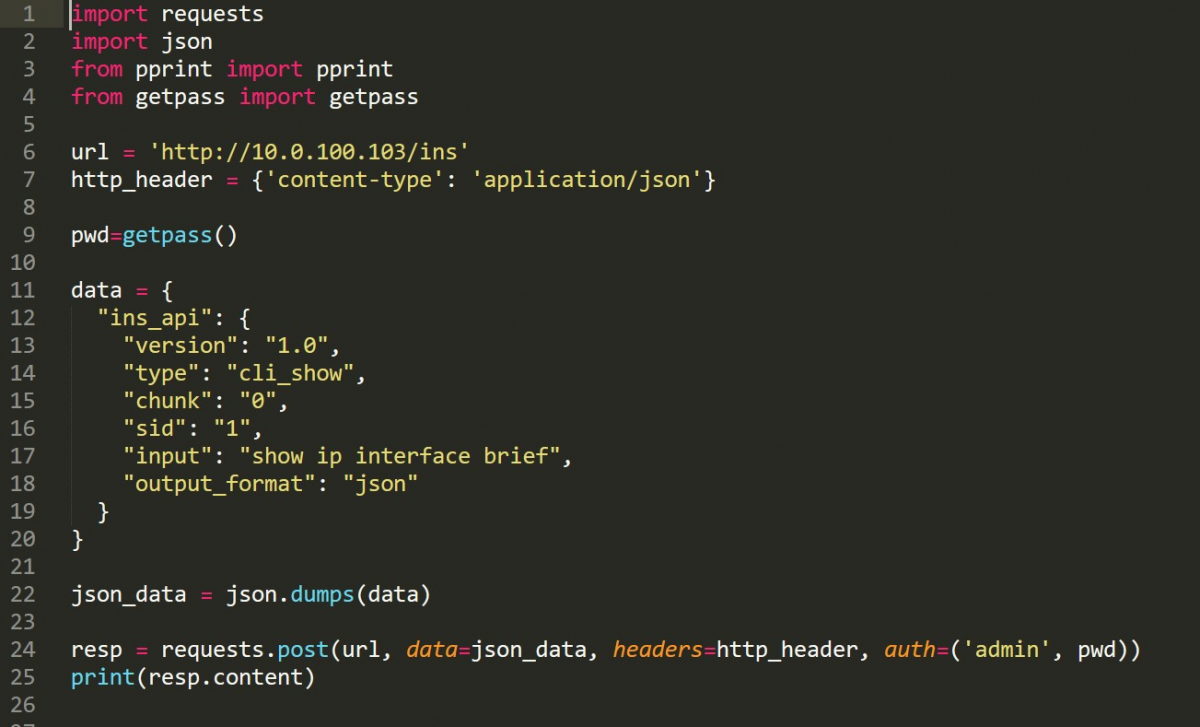
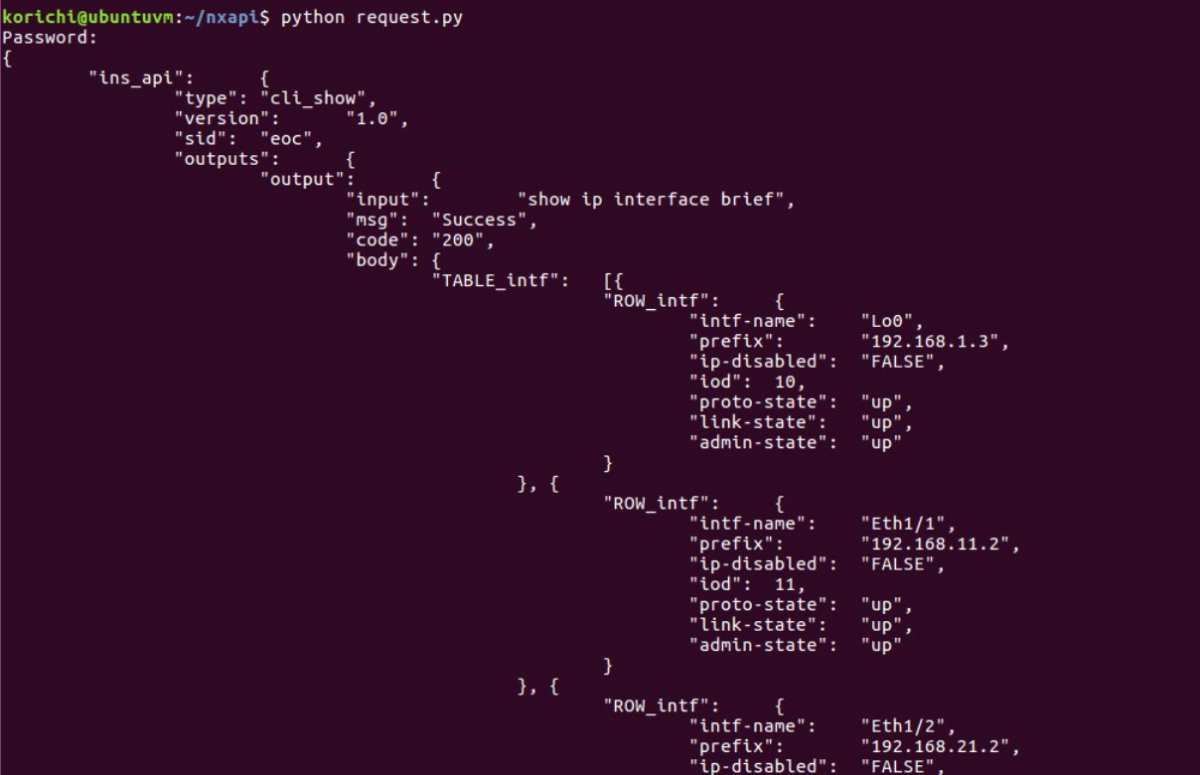
NX-API peut renvoyer un output en XML ou JSON. Dans cet exemple, nous allons examiner l’output en JSON.
Tout de suite, vous constatez que la sortie est structurée et peut être mappée directement à la structure de données du dictionnaire Python.
Une fois celui-ci converti en dictionnaire Python, aucune analyse n’est requise, vous pouvez simplement sélectionner la clé et récupérer la valeur associée à la clé.
Vous pouvez également voir qu’il existe diverses métadonnées dans l’output retournée, telles que le succès ou l’échec de la commande.
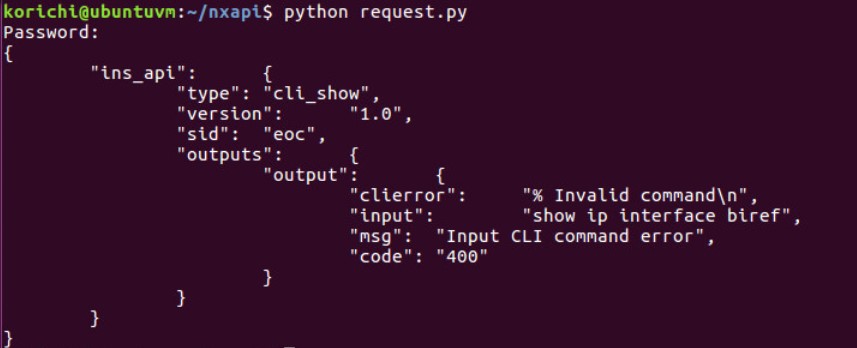
Si la commande échoue, un message indique à l’expéditeur la raison de l’échec. Vous n’avez plus besoin de suivre la commande émise par le programme, car elle vous est déjà renvoyée dans le champ « input”. Il existe également d’autres métadonnées utiles dans l’output, telles que la version NX-API.
Toutefois, les APIs ne résolvent pas tous les problèmes du screen scraping. Parmi leurs inconvénients en commun, nous trouvons :
- L’imprévisibilité : Il n’y a absolument aucune garantie que l’output reste la même entre les différentes versions d’OS. De ce fait, les constructeurs adoptent souvent les best practices afin d’assurer une rétrocompatibilité.
- Adhérence avec le fournisseur (software « lock-in ») : le problème majeur est certainement qu’une fois passé tout ce temps à analyser l’output d’un constructeur et d’une version d’OS, dans notre cas Cisco NX-OS, il faudra répéter ce processus pour le prochain constructeur. Dans ce cas, celui-ci serait très fortement désavantagé car je devrais réécrire tout le code de l’appel API ou bien du screen scraping ! Merci !
L’API, le bon choix pour l’automatisation multi-constructeurs ?
Ce type d’échange facilite la vie des constructeurs et des opérateurs.
Du côté du constructeur, ils peuvent facilement transférer des informations de configuration et d’état. Ils peuvent ajouter des champs supplémentaires lorsque la nécessité d’exposer des données supplémentaires se fait sentir en utilisant la même structure de données.
Côté opérateur, ils peuvent facilement récupérer les informations et s’en servir pour leurs besoins.
Les questions sont généralement centrées sur le format et la structure de l’automatisation.
En fin de compte, le marché global pourrait imposer un format de données à l’avenir. En attendant, il existe d’autres façons de faire pour résoudre les problèmes cités précédemment, comme OpenConfig et le framework NAPALM. Ces dernières, feront sûrement l’objet d’un prochain article au regard de leur importance dans l’automatisation multi-constructeurs.


