

La révolution du Cloud Computing
Avec l’avènement des plateformes IaaS dans les années 2000, les entreprises ont commencé à s’affranchir de leurs infrastructures hébergées dans les datacenters en les délégant progressivement à des tiers et principalement chez les Cloud Providers.
Nous sommes alors passés de l’artisanat du serveur unique avec toutes ses propres dépendances et configurations à l’industrialisation de sa genèse : le provisionnement d’un serveur prenait il y a quelques temps des semaines et parfois des mois à être mis en place. Il y a bien sûr les questions auxquelles nous arrivons rarement à y répondre correctement : combien de mémoire, de compute et de stockage. Commence alors la longue étape que nous appelons chez Metanext : le « au cas où » ! Après sa création, il fallait maximiser son usage, sa rentabilité et prévoir son remplacement.
Les applications destinées à être hébergées sur ce serveur deviennent multiples. Les problématiques de partage de ressources deviennent critiques. A cela, se rajoute un manque de flexibilité parfois étouffant.
L’arrivée de l’IaaS a accéléré ces phases de provisionnement et se sont encore développés avec l’arrivée des concepts de l’infrastructure as code. Cette dynamique s’accompagne d’un grand déplacement des responsabilités : le monde applicatif découvre le fameux « you build it, you run it ».
Cette révolution de l’infrastructure s’est accompagnée d’une autre révolution : celle du monde applicatif. Les architectures logicielles vivent elles aussi des bouleversements constants : certaines d’entre elles que nous croyons il y a peu à la pointe, sont en train de disparaître et devenir “legacy. Les monolithes représentaient une norme dans nos structures applicatives, mais au fil des années, d’autres architectures ont vu le jour comme les micro-services portant la promesse d’un code centré sur le métier, scalable et facilement déployable.
Ces avancées majeures ont facilité la vie des développeurs et des opérationnels, réconcilié le métier et l’univers applicatif et ramené de l’agilité à nos organisations et aujourd’hui, nous assistons à l’émergence et la démocratisation d’un nouveau style d’architecture dit Serverless.
Nous essaierons tout au long de cet article d’expliquer ce nouveau paradigme. Nous présenterons ensuite quelques concepts clés qui gravitent autour de ce concept notamment des acronymes FaaS et BaaS. Nous nous intéresserons par la suite au fonctionnement et aux secrets d’une plateforme dite Serverless. Enfin, nous aborderons aux défis rencontrés par les nouveaux adeptes des architectures Serverless.
A la découverte du Serverless Computing
Le Serverless Computing ou informatique sans serveur tend à rapprocher le développeur du métier tout en lui offrant le luxe de s’abstraire du “fardeau” de l’infrastructure. Nous pouvons aussi présenter ce paradigme comme suit : une plateforme permettant d’exécuter des tâches sans états, déclenchées par l’arrivée d’un ou plusieurs événements, montant automatiquement en charge et facturées à l’exécution. Cette dernière définition rajoute de nouvelles notions à ce concept du Serverless. Nous parlons de tâches, d’événements et de facturation à l’usage.
Une autre définition courante tend à présenter le Serverless Computing comme un service cloud managé qui offre au développeur le luxe de l’abstraction de l’infrastructure : ce dernier n’interviendra que lors de la phase d’implémentation en codant sa fonctionnalité et paramétrant son exécution.
En réalité, l’infrastructure existe toujours, elle est même au cœur de l’innovation amenée par ce paradigme comme nous allons l’aborder dans la suite de cet article.
Avant de faire une immersion complète sur le fonctionnement d’une plateforme Serverless, il est important d’expliciter deux notions fondamentales : le BaaS et le Faas que nous détaillerons dans le paragraphe suivant.
Le duo FaaS & BaaS
La notion de tâche ou d’exécution que nous avons évoquée représente la partie visible des applications Serverless : le FaaS. La Function as a Service s’accompagne d’un nouveau modèle de déploiement : la fonction. Elle va être exécutée dans un environnement isolé et déclenchée par l’arrivée d’un événement.
Le Backend as a Service représentait historiquement les applications tierces que des services vont consommer comme une API Gateway ou un service type Auth0. Actuellement, le terme est utilisé pour décrire les services de stockage dans un univers Serverless comme la base de données DynamoDB chez AWS.
Maintenant que ces concepts sont acquis, intéressons-nous à la partie cachée de l’Iceberg : la plateforme.
Le Fonctionnement d’une plateforme Serverless
Une plateforme Serverless est fondamentalement destinée aux développeurs en leur offrant plusieurs fonctionnalités : La première est bien évidemment l’écriture de son code qui représente la fonction. Cette dernière peut s’écrire dans n’importe quel langage de programmation.
Ensuite, afin de déclencher l’exécution de cette fonction, un ensemble de « triggers » sont proposés comme un appel HTTP ou bien un CRON qui s’actionne à intervalle de temps régulier. La fonction est alors exécutée et son résultat est retourné à l’utilisateur ou envoyé vers un autre service type FaaS ou BaaS.
Ce dernier sous la forme d’une base de données peut, à titre d’exemple, sauvegarder les données d’un service d’authentification pour authentifier un token utilisateur (applicatif ou technique) avant de lancer la réalisation de la fonction. Cet enchaînement représente actuellement la construction des systèmes ou architectures sans états : une succession d’appels orchestrés à des fonctions comme c’est le cas des Step functions sur la plateforme AWS.
Le résultat de ces manipulations est une complète abstraction de l’infrastructure : une absence totale de contrôle sur les environnements de déploiement, aucune intervention lors des phases de mise à l’échelle et une facturation restreinte à la consommation.
Mais comment font les cloud Providers pour mettre en place cette infrastructure ?
Pour répondre à cette question, essayons de diviser la problématique :
- Où mon code est-il exécuté ?
- Comment il est exécuté ?
La réponse à la première question est la suivante : votre code est exécuté dans l’infrastructure du cloud provider. Mais il est considéré non sécurisé et potentiellement très dangereux pour les autres services hébergés dans la même infrastructure.
Pour l’isoler, les CSP vont utiliser le système de SandBox basé sur les conteneurs comme gVisor pour GCP ou Firecracker pour AWS. Ainsi, votre code sera exécuté dans des conteneurs isolés qui auront trois spécificités :
- La montée en charge automatique
- La longue durée de vie pour répondre à plusieurs invocations
- Des conteneurs dédiés par fonction
Pour répondre à la deuxième question, nous allons nous attarder sur un concept fondamental : le cold start. Lors de la première invocation de votre fonction, plusieurs étapes sont exécutées pour la mettre en place :
- Un scheduler va choisir sur quelle la machine physique le conteneur va être créé
- Le conteneur est alors démarré et configuré
- Un environnement d’exécution pour le langage choisi est lancé dans le conteneur
- Le code est chargé et initialisé
Appelons N le nombre d’invocation de notre fonction. Lorsque N > 0 et que le nombre de conteneurs existants ne suffit pas à répondre à la demande, plusieurs conteneurs similaires sont créés pour répondre à la montée en charge. Quand N diminue, ces conteneurs sont mis au ralenti (Idle) ou tués.
Si N=0 pour un certain lapse de temps, tous les conteneurs sont tués et la toute première invocation fera appel au principe du cold start pour recréer un conteneur qui résultera en une réponse plus lente.
Les défis du monde Serverless
Une enquête en 2019du Serverless Framework s’est intéressée aux défis que rencontrent les développeurs lors de leur passage dans un environnement Serverless.
Sans surprise, les aspects liés aux tests, au monitoring et au débogage des fonctions et des systèmes occupent le podium.
Les raisons derrière ce trio sont multiples et que nous avons résumé comme suit :
- Le passage vers des systèmes distribués
- Le manque d’observabilité de certains composants ou briques internes
- L’aspect asynchrones des transactions
- L’impossibilité d’accéder à l’infrastructure sous-jacente
- Les limitations de compute chez certains providers
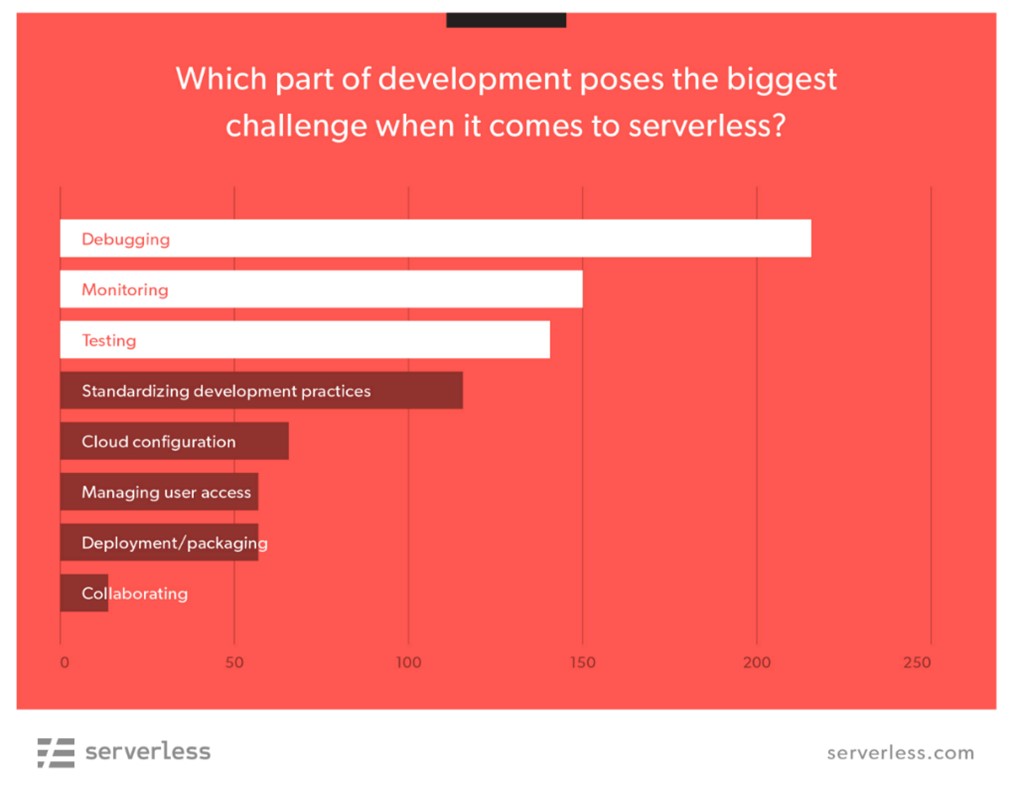
Figure1: Serverles Framework Survey 2019
Pour faire face à ces défis, plusieurs outils sont apparus sur le marché autre que les outils proposés par les fournisseurs de Cloud. Ils abordent ces problématiques sous différents angles.
De part son aspect distribué, la meilleure technique utilisée actuellement pour le débogage est le Traçage.
Chaque composant du système va rajouter, si l’information est absente, des données permettant de retrouver le cheminement de l’exécution d’une requête http ou autres stimuli de notre système. Ce traçage servira aussi à la résolution de notre deuxième problème qui est le monitoring.
Pour avoir un monitoring juste et performant, l’état de notre système doit être jugé selon 5 critères fondamentaux :
- La latence
- Le trafic
- Les erreurs
- La saturation
- Les KPI métiers
Pour répondre à ces critères, les outils apparus sur le marché ont un ensemble de points communs qu’on résume comme suit :
- L’agrégation des logs, des métriques et des traces
- La proposition d’un dashboard unique de supervision apportant une vision globale du système : FaaS et BaaS
Parmi les acteurs du marché nous pouvons citer des solutions comme Dashbird, SignaFx ou bien Espagon. Ces outils gèrent dans la majorité des cas les différentes solutions FaaS et Baas proposées par les fournisseurs Cloud principaux à savoir AWS, Azure ou GCP.
Les tests sont un aspect primordial pour les développeurs et cette règle reste tout à fait valable pour les plateformes serverless. Que nos tests soient unitaires, d’intégration ou de charges, plusieurs outils ont vu le jour et qui s’intègrent parfaitement à notre chaîne CICD comme par exemple Artillery pour AWS Lambda ou Loader.io pour les Azure Functions qui font partie de la catégorie tests de performance et d’acceptance.
En conclusion
Tout au long de cet article, nous avons voulu présenter l’approche Serverless d’un point de vue utilisateur qui n’est autre que le développeur. Nous avons aussi tenu à montrer le fonctionnement interne d’une plateforme Serverless afin de démystifier certains aspects liés au provisionnement et au contexte d’exécution de notre code. Enfin, nous avons abordé le thème de l’adoption de ces plateformes en s’intéressant aux défis que rencontrent les développeurs dans leurs voyages Serverless.
Pour conclure cet opus, les serveurs sont au cœur du Serverless Computing et toute l’intelligence de ces services réside dans l’isolation et l’optimisation des conteneurs. Cependant, nous vous conseillons d’accorder une grande attention à l’optimisation du code de vos fonctions afin de minimiser leur temps d’exécution, leurs consommations de ressources qui impacteront fortement votre facture et notre environnement.
par Ahmed CHAARI, Architecte Solutions.