
Je suis heureux de vous retrouver pour la deuxième partie de mon Vademecum du Stockage en 2020-2012.
Et zou, bien souple sur les chevilles, on garde le rythme …
Sans oublier le PodCast « Unleash your storage passion » http://www.podcast.unleash-your-storage-passion.fr/
Cloud Hybride
Déjà des pages de blabla, et toujours pas un mot sur le Cloud ?!? Vous avez raison, c’est le moment d’en parler.
C’est un très vaste sujet et je voudrais surtout me concentrer ici sur la grande diversité des usages possibles en mode hybride.
Et pour ce faire, je vais me permettre de m’appuyer sur le Gartner qui a fait un très bon travail dans ce domaine pour tenter de clarifier les débats.
Stockage primaire « On Premise » avec stockage secondaire dans le Cloud public
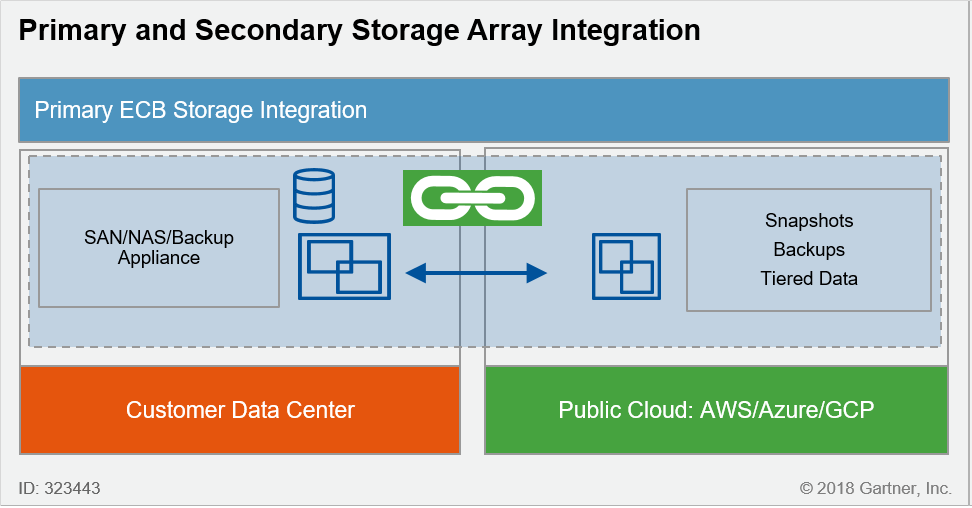
- Mise en œuvre simple sans impact majeur sur le site principal
- Réduction des coûts pour le stockage secondaire
- Stockage secondaire dans le format propriétaire du Coud public (sauf solutions proposées par des acteurs comme NetApp ou Pure Storage)
Passerelle pour le partage de fichiers
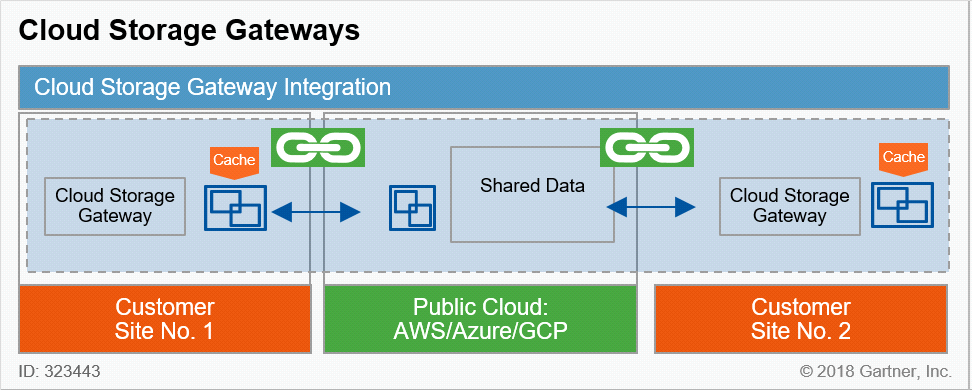
- Accès à distance, depuis n’importe où
- Réduction et chiffrement des données pour l’accès à distance
- Performances dépendantes de l’efficacité du cache
Colocation avec le Cloud public
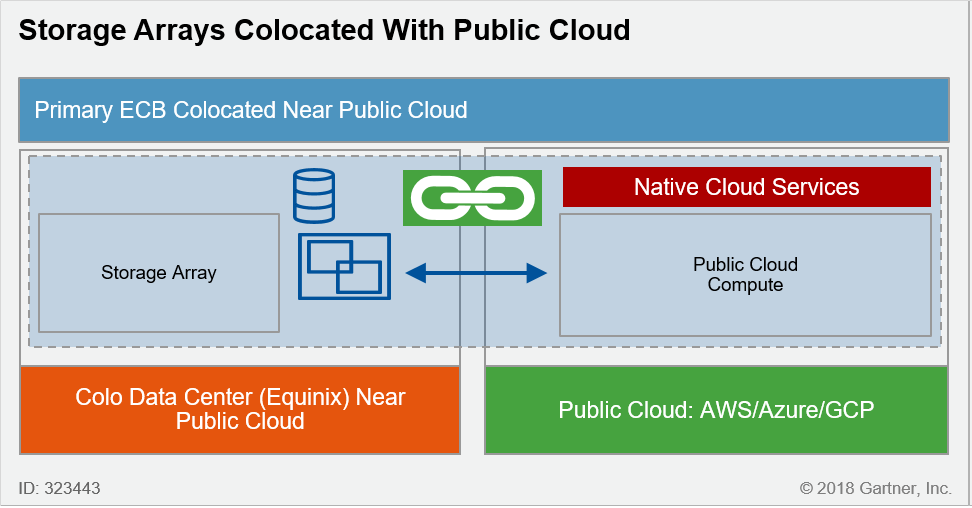
- Extension naturelle du stockage dans le Cloud, avec la même technologie de bout en bout (ex : NetApp et Pure Storage)
- Accès immédiat au portefeuille de services du Cloud public
- Mise en œuvre plus complexe
- Impact majeur de la latence entre les 2 sites (normalement sous contrôle grâce à la colocation)
Plate-forme SDS hybride
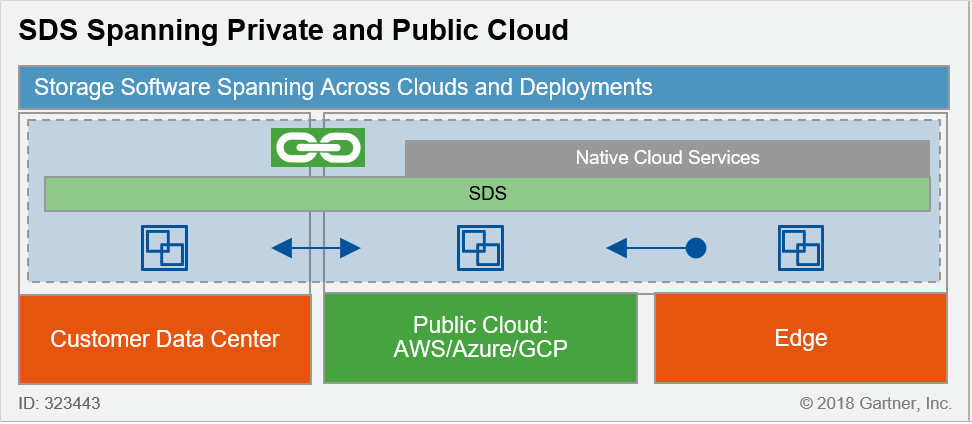
- Architecture native pour les plates-formes de Stockage Objet ou NAS « Scale-Out » (ex : Scality, Cloudian, Qumulo, …)
- Vision uniforme de la donnée indépendamment de la localisation physique
- Très haute résilience et évolutivité naturelle
- Coût important de l’infrastructure initiale
Plate-forme hybride globale
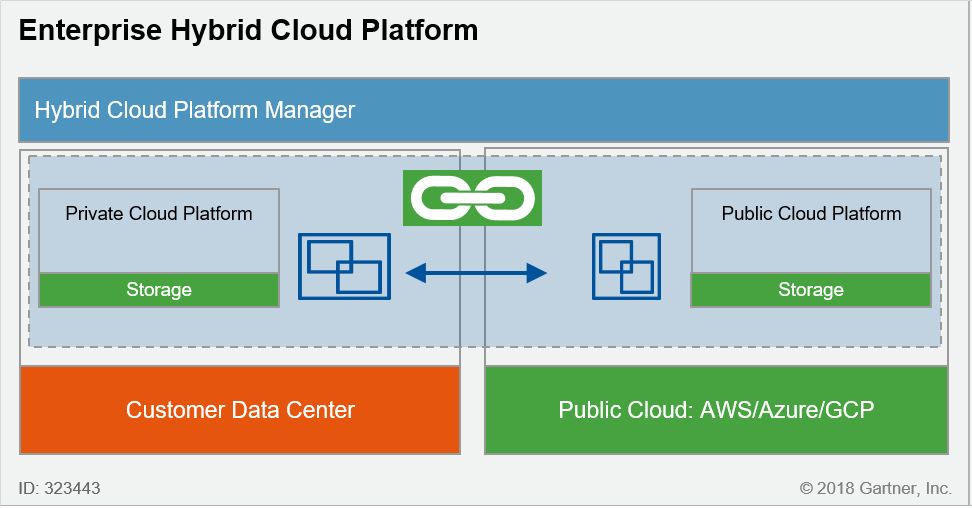
- Plate-forme cohérente de bout en bout (ex : VMware on AWS, Azure Stack)
- Mise en œuvre simplifiée avec services intégrés (ex : MCO Infrastructure)
- Solution 100% propriétaire
Et cette liste n’est pas exhaustive ! Elle permet au moins de comprendre pourquoi le Cloud s’invite maintenant dans tous les projets d’évolution ou de refonte du stockage.
Au-delà de ses exemples d’architecture, je souhaite mettre l’accent sur 2 approches Storage as a Service (STaaS) qui apparaissent de plus en plus souvent dans les appels d’offres : le Backup as a Service (BaaS) et le Disaster Recovery as a Service (DRaaS).
Dans les 2 cas, la principale motivation de la DSI, poussée par la DG et la DF, est de transformer des CAPEX en OPEX sur des sujets, certes importants, mais qui sont des sujets vus comme techniques. En effet nous sommes loin des enjeux Métiers même si le jour (mal)venu, le Métier comprendra immédiatement tout ce qu’il a perdu si ces sujets ont été traités avec « désinvolture ».
D’une certaine façon, la recrudescence du Ransomware et la COVID ont remis les pendules à l’heure.
Les solutions sont de plus en plus nombreuses, soit avec un fournisseur de services globale (ex : AntemetA), soit avec une solution nativement pensée pour le Cloud avec un haut niveau d’automatisation et de supervision embarqué (ex : Druva pour le BaaS, Datrium pour le DRaaS).
Mon message est simple : à étudier de près systématiquement dans le cadre d’un AO, en prenant en compte tous les aspects bien sûr, notamment :
- Sécurité (accès, chiffrement)
- Temps de latence et débit
- Suivi (rapports) et supervision
- Approche multi-cloud pour la pérennité
- Automatisation des processus (ex : restauration, test à blanc, bascule, …)
- Compétences requises
- Et bien sûr le coût (en mode nominal, en débordement, en test, en bascule, …) et les capacités de contrôle (merci le FinOps) !
Et pour faire une petite pause,
- How to architect Storage Applications for the Public Cloud economy
https://www.youtube.com/watch?v=qGce7nXEUYE&list=PLH_ag5Km-YUY5M5HFLHsJNDZt35n8vGdD&index=18
Conteneurs & K8s
Quitte à évoquer de nouvelles façons de faire, autant poursuivre avec les conteneurs et K8s.
Inutile d’épiloguer longuement sur le déploiement massif (voie le déferlement dans certains cas !) des conteneurs au sein des entreprises, de toute taille et dans tous les secteurs.
En revanche, il est plus intéressant de souligner que l’usage des conteneurs concerne de plus en plus les applications en production, notamment grâce à K8s en tant qu’orchestrateur standard « de facto ». Et qui dit production, implique performance, haute disponibilité et résilience.
De plus, le conteneur est tellement simple à déployer, qu’il est envisagé de plus en plus comme enveloppe pour des données vives comme celles gérées par les bases de données.
Je ne me lancerai pas ici sur la pertinence ou non d’une telle démarche. Je laisse cela aux spécialistes.
En revanche, c’est un fait chez des clients de plus en plus nombreux. Il est donc impératif de proposer un stockage de production pour héberge ces données persistantes. Nous sommes très loin des contraintes simples des conteneurs « stateless » !
Heureusement il existe la solution magique : le plugin CSI (Container Storage Interface) !
Après quelques années de normalisation, il est aujourd’hui devenu standard chez tous les fournisseurs de stockage comme NetApp, Pure Storage, Dell/EMC et HPE. Les « pure players » du début sont devenus rares, à part Portworx ou Robin.io.
Ce plugin permet de déléguer au stockage NAS ou SAN la gestion des volumes nécessaires aux conteneurs, et d’assurer la persistance des données au-delà de la vie parfois éphémère du conteneur.
Ils sont disponibles simplement via les plates-formes Git mises à disposition par les fournisseurs.
Pour se persuader définitivement de l’intérêt du plugin CSI, il suffit de regarder l’annonce de Google qui a certifié début 2020 6 pilotes CSI (chez les fournisseurs cités précédemment) comme « Anthos Ready Storage » pour sa solution Anthos de déploiement de conteneurs avec K8s On-Premise et Multi-Cloud !
Exploitation
La production amène obligatoirement à regarder comment l’exploitation du stockage a évolué.
Seuls les plus de 40 ans ont connu les installations de baies sur plusieurs jours, avec validation de la configuration des « LUNs » par le support, sans possibilité de revenir simplement sur l’organisation des disques une fois la configuration installée !
Depuis plusieurs années déjà, la mise en œuvre d’une baie se fait en quelques minutes, installation physique comprise, et les volumes totalement flexibles sont présentés aux serveurs en moins d’une demi-heure. Il suffit d’un nom et d’une taille pour configurer un volume. C’est tout ! Génial.
Ces derniers temps l’accent est mis sur l’automatisation des processus d’allocation du stockage afin de rendre fluide et rapide la mise à disposition de nouveaux environnements sous la forme de VMs ou de conteneurs.
Les « administrateurs » de stockage doivent maintenant être capables de réaliser des scripts avec VMware VRA/VRO ou des playbooks Ansible. Heureusement des exemples existent chez les fournisseurs sur leur plate-forme Git !
Mais ce n’est pas tout. L’évolution majeure concerne surtout la supervision du stockage et l’anticipation des pannes !
La connexion directe des baies ou des serveurs au support (suivant les règles de sécurité imposées par le client) existe depuis longtemps afin de remonter en temps réel les alertes et les incidents, et permettre le cas échéant au support de se connecter afin de corriger le problème.
Mais il est encore plus sympathique que le stockage puisse se débrouiller tout seul pour détecter un comportement anormal (ex : mauvaise performance, erreurs répétitives, …) et déclencher l’application d’un correctif ou la mise hors service du module en question.
Et encore mieux, être informé par le support qu’un problème a été identifié sur un environnement similaire chez un autre client, que le correctif existe et qu’il est pertinent de l’appliquer.
Science-fiction ? non ! IA tout simplement. Et même AIOps !
AIOps décrit l’intrusion de l’AI dans l’exploitation, avec la promesse de radicalement simplifier les opérations au quotidien sur tous les composants de l’infrastructure IT : serveur, stockage, réseau services cloud et aussi les applications.
L’AIOps applique les principes analytiques du Big Data et Machine Learning (ML) à la supervision, la télémétrie et tous les journaux générés par les différents systèmes, On-Premise et dans le Cloud, afin d’automatiser les routines d’allocation de ressources en fonction des besoins à venir et d’anticiper les incidents en amont pour les résoudre avec efficacité au plus vite, c-a-d avant même qu’ils se produisent !
Dans le domaine du stockage, Nimble a été le premier il y a quelques années a introduire massivement l’IA dans la supervision des baies et depuis tous les constructeurs ont pris la même direction.
Aujourd’hui, une solution de production digne de ce nom se doit d’avoir une autonomie de prise de décision pour garantir les niveaux de services grâce à l’IA embarquée et/ou disponible dans le centre de support et de maintenance avec le Datalake de tous les incidents collectés partout dans le monde.
A ce titre, ProphetStor propose des solutions très intéressantes pour diminuer les incidents et optimiser les performances des environnements de stockage. Un petit coup d’œil est intéressant.
Pour parfaire ses connaissances sur l’IA, voici 2 vidéos su SNIA
- What every technologist should know about AI and Deep Learning
https://www.youtube.com/watch?v=j96HMUNkKXw&list=PLH_ag5Km-YUY5M5HFLHsJNDZt35n8vGdD&index=15
- The impact of AI on Storage and IT
https://www.youtube.com/watch?v=Py2LkDWNjxU
Et comme j’ai très souvent cité le SNIA (que je remercie pour les nombreuses vidéos très instructives), je me dois de vous recommander la vidéo suivante sur Swordfish.
Swordfish est le résultat des nombreux travaux réalisés par le SNIA afin de proposer une solution universelle (encore et toujours) d’administration de tous les types de stockage (bloc, ficher, objet), pour tous les composants (serveur, baie, fabric). C’est beau non ?
Cela rappellera sans doute aux plus anciens l’initiative SMI-S du SNIA qui n’a jamais vraiment abouti.
Mais bon, soyons optimistes (même si j’ai de sérieux doutes !).
https://www.youtube.com/watch?v=1e4p9rhc5I4&list=PLH_ag5Km-YUY5M5HFLHsJNDZt35n8vGdD&index=5
Et enfin, avant de passer au dernier sujet, un petit mot sur la facturation des ressources mises à disposition.
Pour moi, cela se décline de deux façons.
Tout d’abord la capacité de mettre à jour une baie de stockage par simple remplacement des « contrôleurs », et donc sans migration des donnée (Youpi !), à un coût connu à l’avance.
Et surtout éviter l’AO au bout de 3 ans pour mettre en concurrence le fournisseur en place et éviter de payer la maintenance 2 à 3 fois plus chère, et prendre le risque d’un changement de solution et donc d’une migration des données avec les coûts et les risques induits.
Pure Storage a été le premier a proposé le contrat Evergreen pour supprimer cet écueil et finalement pérenniser le client. Heureusement, aujourd’hui tout le marché a suivi (ou presque). C’est devenu un pré-requis dans un AO.
L’autre point est la facturation à l’usage, à la hausse et à la baisse, comme dans le Cloud, avec suffisamment de ressources disponibles pour faire face aux besoins. Sur ce sujet, HPE tire le marché avec son programme GreenLake qui concerne peu à peu tous les équipements comme les serveurs et le stockage. Mais les autres fournisseurs suivent de près.
Archivage des données
Pour finir ce très long « Vademecum » (désolé !), je reviens sur la donnée.
Depuis le début de document, nous l’avons sollicitée dans tous les sens. Il est donc temps qu’elle prenne un repos bien mérité, c-a-d être archivée.
Mais nous voulons lui laisser le choix de sa résidence finale, avec capacité de changer si besoin : bande, SAN, NAS, cloud, stockage objet, … Et si possible avec une automatisation du déplacement en fonction de règles prédéfinies sur les caractéristiques de la donnée.
Il est donc nécessaire de pouvoir y accéder sans savoir sur quel support elle se trouve à un instant donné, et la déplacer simplement, sans impact sur les applications qui la manipulent.
De plus, cette donnée conserve une certaine valeur. Et peut-être dans le temps, elle prendra encore plus de valeur. Il faut donc enrichir ses métadonnées pour pouvoir l’identifier comme pertinente en regard d’un nouveau besoin.
Et enfin tout ceci s’inscrit dans le temps, sur plusieurs années, voire dizaine d’années. Il est donc nécessaire de faire abstraction le plus possible du matériel qui va vieillir et devenir obsolète.
Tout ceci ressemble furieusement à une solution HSM avec la gestion multi-tiers, comme celles proposée depuis des années par IBM ou Oracle. Pas tout à fait.
En effet, la combinaison simultanée de tous les besoins amène à envisager des solutions de nouvelle génération comme celles de ScoutAM de Versity, StrongLink de StrongBox ou encore vFILO de Datacore.
Une autre ! une autre ! une autre ! Bon, je cède à la ferveur endiablée d’un public conquis et je fais un rappel. C’est bien parce que c’est vous !
Computational Storage
En bonus, j’aimerais vous parler d’un thème qui devrait devenir un « must » en 2021, le Computational Storage.
Comme de plus en plus d’applications manipulent un volume élevé de données (IoT, IA, Analytique …), le temps imparti pour transférer, analyser et traiter ces données devient un facteur prédominant dans la performance globale.
Le Computational Storage apporte une solution pour optimiser ce lien entre stockage et traitement, notamment pour les besoins Edge.
Cette technologie innovante propose une nouvelle génération de disques SSD avec une capacité de calcul embarquée, afin de traiter la donnée au plus près, pour éliminer les informations inutiles et envoyer les informations pertinentes sur le réseau pour une valorisation plus poussée.
En bref, le Computational Storage facilite la parallélisation des traitements, réduit le trafic sur le réseau et optimise l’usage global des ressources (processeur, mémoire, stockage).
Le schéma ci-dessous décrit ces principes :
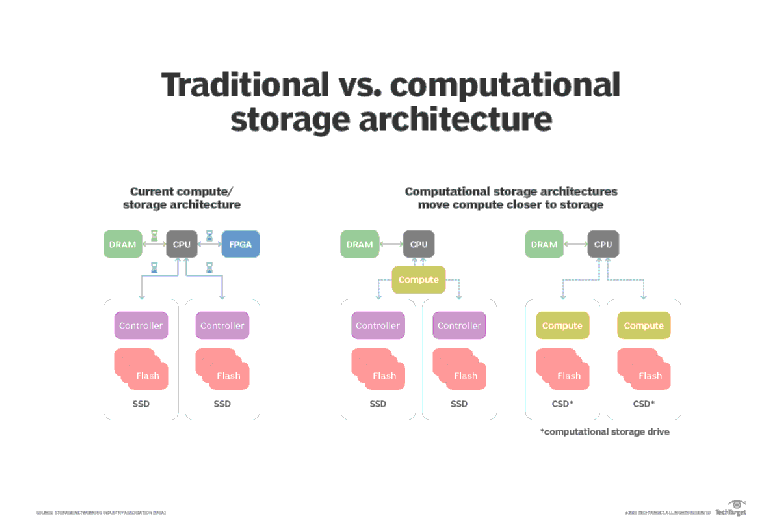
Il existe principalement 2 composants majeurs :
- Computational Storage Drive (CSD) : un disque SSD avec un processeur FPGA ou un ASIC
- Computational Storage Array (CSA) : une baie composée de CSD, avec des processeurs FPGAs en complément
Il existe d’autres déclinaisons et je vous invite à regarder les vidéos proposées ci-dessous, ce sera plus simple et efficace. A ce jour, l’un des principaux acteurs est NGD Systems.
Les cas d’usage pour ce nouveau stockage concernent par exemple les HyperScalers afin d’optimiser l’espace dans les Datacenters, les traitements intensifs pour l’IA et le Machine Learning, l’analyse en temps réel notamment en couplage avec l’IoT, le Content Delivery Network (CDN), … et ce n’est qu’un début !
Ces 2 vidéos de la Storage Developper Conference 2020 du SNIA vous apporteront tous les compléments nécessaires
- Architecture development with Computational Storage
https://www.youtube.com/watch?v=D7FMXfTpVTE&list=PLH_ag5Km-YUY5M5HFLHsJNDZt35n8vGdD&index=9
- Computational Storage workloads – implications for DC architecture
https://www.youtube.com/watch?v=3RyjhLg0UsM&list=PLH_ag5Km-YUY5M5HFLHsJNDZt35n8vGdD&index=17
Cette fois-ci c’est vraiment la fin. Snif…
J’ai eu vraiment beaucoup de plaisir à rédiger ce document. J’espère que vous avez eu aussi du plaisir à le lire.
A bientôt !
Frédéric CHOMETTE, Directeur Solutions